DeepInfra raises $107M Series B to scale the inference cloud — read the announcement

Qwen/
Qwen3-235B-A22B-Instruct-2507
$0.09
in
$0.55
out
/ 1M tokens
| Tier | Input | Output |
|---|---|---|
Priority (1.5×)Learn More | $0.135 | $0.825 |
Flex (0.8×)Learn More | $0.072 | $0.44 |
per 1M tokens
Qwen3-235B-A22B-Instruct-2507 is the updated version of the Qwen3-235B-A22B non-thinking mode, featuring Significant improvements in general capabilities, including instruction following, logical reasoning, text comprehension, mathematics, science, coding and tool usage.


Qwen3-235B-A22B-Instruct-2507
Ask me anything
You need to log in to use this model
Log InSettings
Highlights
We introduce the updated version of the Qwen3-235B-A22B non-thinking mode, named Qwen3-235B-A22B-Instruct-2507, featuring the following key enhancements:
- Significant improvements in general capabilities, including instruction following, logical reasoning, text comprehension, mathematics, science, coding and tool usage.
- Substantial gains in long-tail knowledge coverage across multiple languages.
- Markedly better alignment with user preferences in subjective and open-ended tasks, enabling more helpful responses and higher-quality text generation.
- Enhanced capabilities in 256K long-context understanding.
Model Overview
Qwen3-235B-A22B-Instruct-2507 has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 235B in total and 22B activated
- Number of Paramaters (Non-Embedding): 234B
- Number of Layers: 94
- Number of Attention Heads (GQA): 64 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: 262,144 natively.
NOTE: This model supports only non-thinking mode and does not generate **\<think>****\</think>** blocks in its output. Meanwhile, specifying enable_thinking=False is no longer required.
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our blog, GitHub, and Documentation.
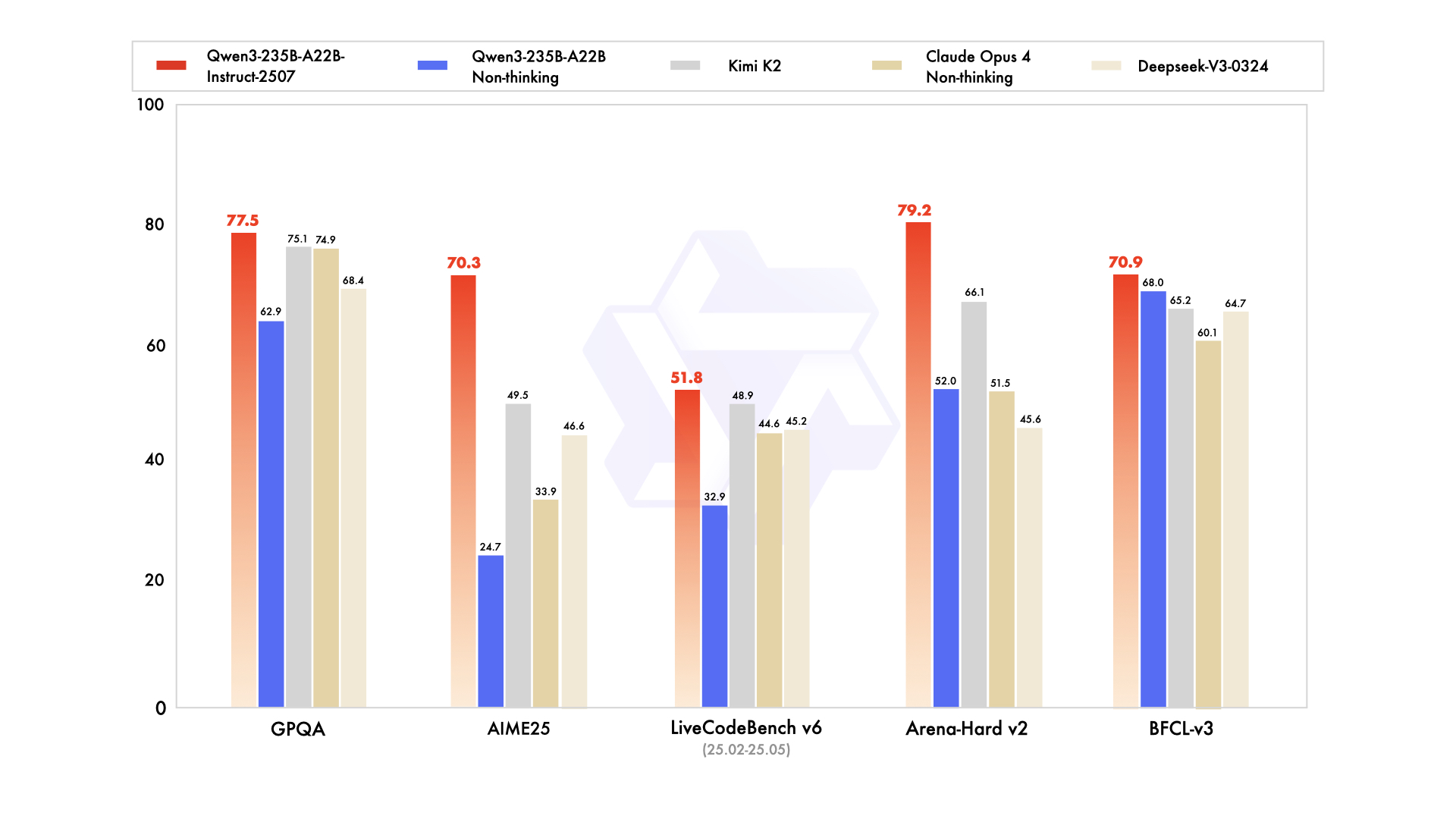
Performance
| Deepseek-V3-0324 | GPT-4o-0327 | Claude Opus 4 Non-thinking | Kimi K2 | Qwen3-235B-A22B Non-thinking | Qwen3-235B-A22B-Instruct-2507 | |
|---|---|---|---|---|---|---|
| Knowledge | ||||||
| MMLU-Pro | 81.2 | 79.8 | 86.6 | 81.1 | 75.2 | 83.0 |
| MMLU-Redux | 90.4 | 91.3 | 94.2 | 92.7 | 89.2 | 93.1 |
| GPQA | 68.4 | 66.9 | 74.9 | 75.1 | 62.9 | 77.5 |
| SuperGPQA | 57.3 | 51.0 | 56.5 | 57.2 | 48.2 | 62.6 |
| SimpleQA | 27.2 | 40.3 | 22.8 | 31.0 | 12.2 | 54.3 |
| CSimpleQA | 71.1 | 60.2 | 68.0 | 74.5 | 60.8 | 84.3 |
| Reasoning | ||||||
| AIME25 | 46.6 | 26.7 | 33.9 | 49.5 | 24.7 | 70.3 |
| HMMT25 | 27.5 | 7.9 | 15.9 | 38.8 | 10.0 | 55.4 |
| ARC-AGI | 9.0 | 8.8 | 30.3 | 13.3 | 4.3 | 41.8 |
| ZebraLogic | 83.4 | 52.6 | - | 89.0 | 37.7 | 95.0 |
| LiveBench 20241125 | 66.9 | 63.7 | 74.6 | 76.4 | 62.5 | 75.4 |
| Coding | ||||||
| LiveCodeBench v6 (25.02-25.05) | 45.2 | 35.8 | 44.6 | 48.9 | 32.9 | 51.8 |
| MultiPL-E | 82.2 | 82.7 | 88.5 | 85.7 | 79.3 | 87.9 |
| Aider-Polyglot | 55.1 | 45.3 | 70.7 | 59.0 | 59.6 | 57.3 |
| Alignment | ||||||
| IFEval | 82.3 | 83.9 | 87.4 | 89.8 | 83.2 | 88.7 |
| Arena-Hard v2* | 45.6 | 61.9 | 51.5 | 66.1 | 52.0 | 79.2 |
| Creative Writing v3 | 81.6 | 84.9 | 83.8 | 88.1 | 80.4 | 87.5 |
| WritingBench | 74.5 | 75.5 | 79.2 | 86.2 | 77.0 | 85.2 |
| Agent | ||||||
| BFCL-v3 | 64.7 | 66.5 | 60.1 | 65.2 | 68.0 | 70.9 |
| TAU-Retail | 49.6 | 60.3# | 81.4 | 70.7 | 65.2 | 71.3 |
| TAU-Airline | 32.0 | 42.8# | 59.6 | 53.5 | 32.0 | 44.0 |
| Multilingualism | ||||||
| MultiIF | 66.5 | 70.4 | - | 76.2 | 70.2 | 77.5 |
| MMLU-ProX | 75.8 | 76.2 | - | 74.5 | 73.2 | 79.4 |
| INCLUDE | 80.1 | 82.1 | - | 76.9 | 75.6 | 79.5 |
| PolyMATH | 32.2 | 25.5 | 30.0 | 44.8 | 27.0 | 50.2 |
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
#: Results were generated using GPT-4o-20241120, as access to the native function calling API of GPT-4o-0327 was unavailable.



© 2026 DeepInfra. All rights reserved.