DeepInfra raises $107M Series B to scale the inference cloud — read the announcement
 Latest article
Latest articleMoonshot AI’s Kimi K3 represents a significant leap in open-weight AI model development. Released on July 16, 2026, this 2.8-trillion-parameter reasoning model has quickly become a focal point for developers seeking frontier-level intelligence with the flexibility of open weights. This analysis evaluates Kimi K3’s technical specifications, benchmark performance, and compares the leading API providers offering […]
 Published on 2026.07.28 by DeepInfraKimi K3 vs Claude Opus 4.8 vs GPT-5.6 Sol: Practical AI Model Comparison
Published on 2026.07.28 by DeepInfraKimi K3 vs Claude Opus 4.8 vs GPT-5.6 Sol: Practical AI Model ComparisonThe three strongest models available on DeepInfra right now don’t separate cleanly by capability tier. Kimi K3, Claude Opus 4.8, and GPT-5.6 Sol all score within 3 points of each other on the Artificial Analysis Intelligence Index. All three support one-million-token context windows. All three handle vision. And yet the right choice for a given […]
 Published on 2026.07.28 by DeepInfraKimi K3 vs DeepSeek V4 Pro vs GLM-5.2: Open-Weight AI Model Comparison
Published on 2026.07.28 by DeepInfraKimi K3 vs DeepSeek V4 Pro vs GLM-5.2: Open-Weight AI Model ComparisonIn the span of three months, three Chinese AI labs shipped open-weight models that individually would have rewritten the frontier story. Together, they signal something more structural: the open-weight tier is no longer a budget alternative to closed models. Kimi K3 (Moonshot AI, July 2026), DeepSeek V4 Pro (DeepSeek, April 2026), and GLM-5.2 (Zhipu AI, […]
 Published on 2026.07.22 by DeepInfraHosted Agents: your own always-on AI agent, from $13/month
Published on 2026.07.22 by DeepInfraHosted Agents: your own always-on AI agent, from $13/monthOne click gives you a dedicated, isolated AI agent, pre-wired to fast inference and ready to work the moment it boots. No VMs, no SSH hardening, no patching. From $13/month, and idle is free.
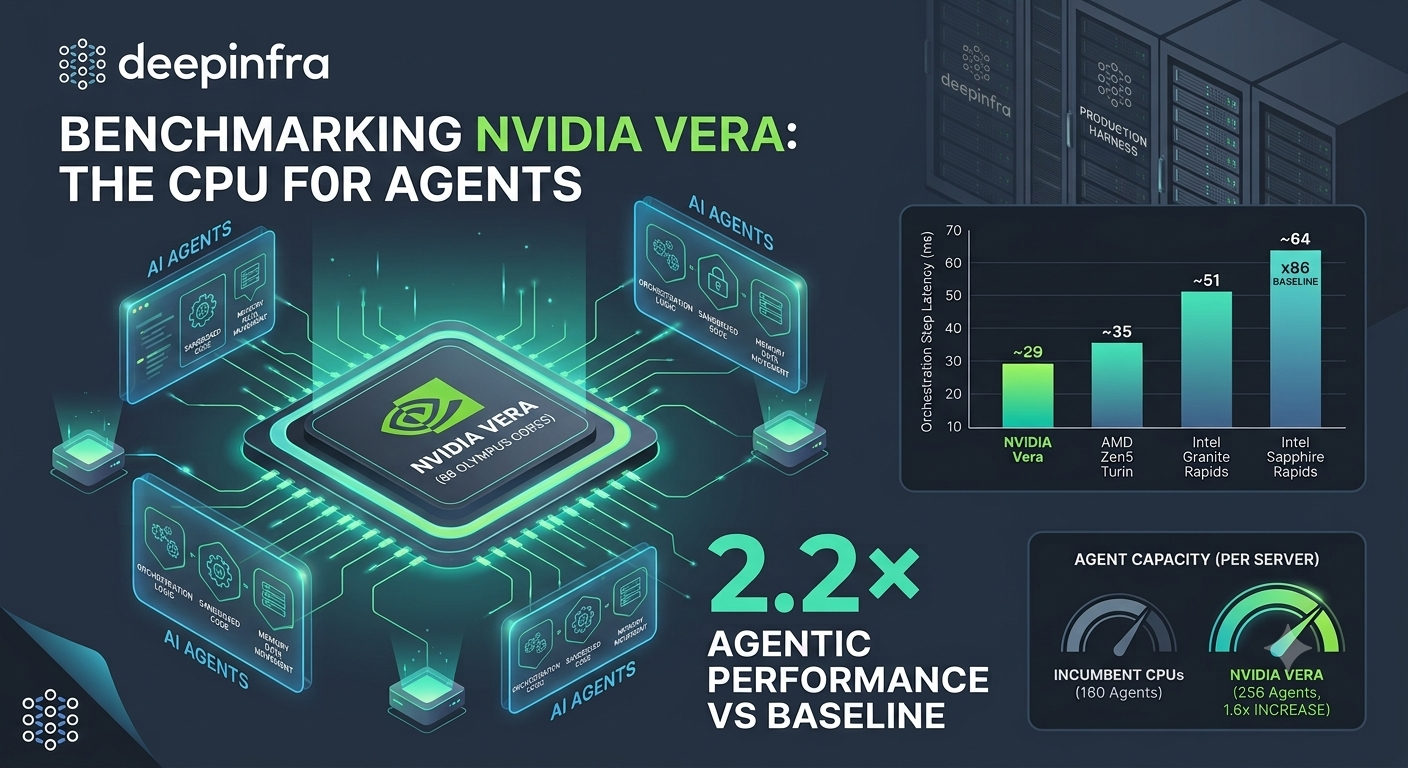 Published on 2026.07.21 by DeepInfraWe Benchmarked NVIDIA Vera, the CPU for Agents. Here's What We Measured
Published on 2026.07.21 by DeepInfraWe Benchmarked NVIDIA Vera, the CPU for Agents. Here's What We MeasuredDeepInfra runs AI agents in production, so when NVIDIA built a CPU for agents, we measured it ourselves with our own harness, our own agent, and a methodology we locked before the hardware arrived.
 Published on 2026.07.16 by Aray SultanbekovaDeepInfra Now Serves NVIDIA Nemotron 3 Embed: Frontier Retrieval for RAG and Agents
Published on 2026.07.16 by Aray SultanbekovaDeepInfra Now Serves NVIDIA Nemotron 3 Embed: Frontier Retrieval for RAG and AgentsDeepInfra now serves NVIDIA Nemotron 3 Embed, the industry's leading open embedding model for enterprise search and agentic retrieval, available today in both 8B and 1B sizes.
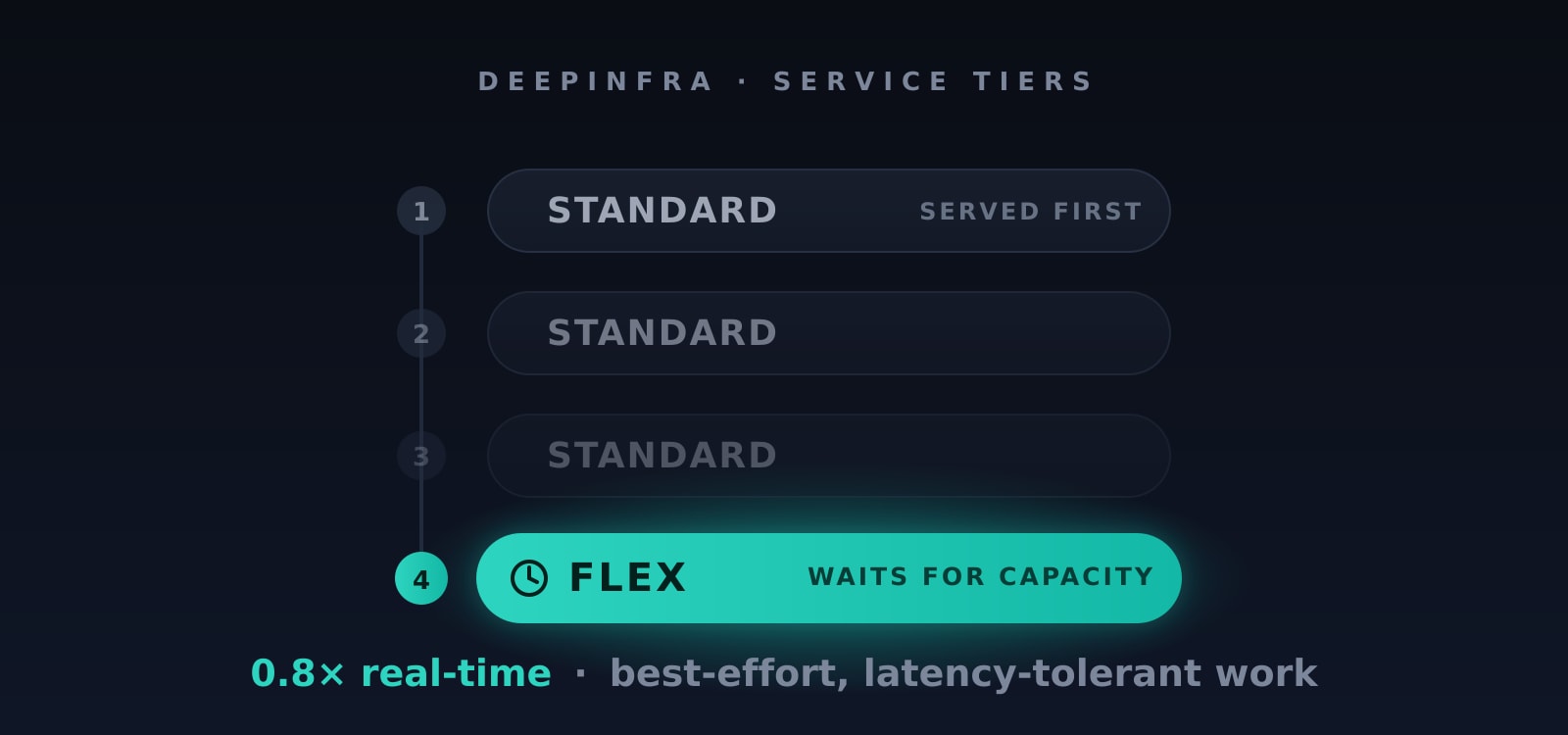 Published on 2026.07.14 by DeepInfraIntroducing the Flex Service Tier: Cheaper Inference When You Can Wait
Published on 2026.07.14 by DeepInfraIntroducing the Flex Service Tier: Cheaper Inference When You Can WaitRun latency-tolerant work at 0.8× real-time — best-effort, sheddable, same OpenAI-compatible API.



© 2026 DeepInfra. All rights reserved.