DeepInfra raises $107M Series B to scale the inference cloud — read the announcement

Google DeepMind’s Gemma 4 scored 88.3% on AIME 2026 mathematics benchmarks in its 26B MoE variant — compared to 20.8% for its predecessor, Gemma 3 27B. That’s not an incremental update. The family spans four model sizes designed for hardware targets as different as a Raspberry Pi and a consumer GPU workstation, with every model open-weight and released under the Apache 2.0 license.
The most interesting architectural decision in the 26B model is its Mixture-of-Experts design: 25.2 billion total parameters, but only 3.8 billion active during inference — putting it at roughly the speed of a 4B dense model while clearing benchmarks that dense models at that size simply can’t match. Pair that with a 256K token context window and native function calling support, and it’s a reasonable fit for agentic workflows, not just conversational use. On LiveCodeBench v6, the 26B variant scores 77.1%, up from 29.1% for Gemma 3 27B — a gap that matters directly if you’re building in the coding or reasoning space.
What Makes This Model Different
Gemma 4 is a family of models spanning from sub-5B edge-optimized variants up to a 31B dense model, each built around a hybrid attention mechanism that interleaves local sliding window attention with full global attention. The 26B A4B model is a Mixture-of-Experts architecture: while it only activates 4 billion parameters per token during generation, all 26 billion parameters must be loaded into memory to maintain fast routing and inference speeds. That makes it behave more like a 4B-parameter dense model at runtime, while drawing on the knowledge encoded across 25.2B total parameters.
On the architecture side, global attention layers use unified Keys and Values, and apply Proportional RoPE (p-RoPE) — a design choice that keeps memory overhead manageable for long-context tasks. The 26B A4B and 31B models support a 256K token context window, while the edge variants (E2B/E4B) support 128K. The “E” in E2B and E4B stands for “effective” parameters, and the smaller models incorporate Per-Layer Embeddings (PLE) to maximize parameter efficiency in on-device deployments.
Benchmark results (instruction-tuned, thinking enabled):
| Benchmark | Gemma 4 26B A4B | Gemma 4 31B | Gemma 3 27B |
|---|---|---|---|
| AIME 2026 (math, no tools) | 88.3% | 89.2% | 20.8% |
| LiveCodeBench v6 (coding) | 77.1% | 80.0% | 29.1% |
| GPQA Diamond (science) | 82.3% | 84.3% | 42.4% |
| MMMLU (multilingual) | 86.3% | 88.4% | 70.7% |
| MMMU Pro (vision reasoning) | 73.8% | 76.9% | 49.7% |
| τ²-bench (agentic tool use) | 68.2% | 76.9% | 16.2% |
The jump from Gemma 3 27B is substantial across every category — most notably in math, coding, and agentic benchmarks, where scores roughly tripled in some cases. The dense 31B model wins on raw quality across the board, but the margins are relatively small — typically 2–4 points. Whether that delta justifies the inference cost difference depends on your workload.
Gemma 4 adds several capabilities that were absent or limited in Gemma 3: native system prompt support, configurable thinking/reasoning modes (triggered via the <|think|> token), and native function calling across all model sizes. Extended multimodal support processes text and images with variable aspect ratio and resolution (all models), video, and audio — with audio natively supported on the E2B and E4B models. The 26B A4B model handles text and image inputs. All models cover 140+ languages with training that targets cultural context, not just token-level translation.
If you want to explore the full multimodal model catalogue on DeepInfra, the models page lists all available vision and multimodal variants alongside their specs and pricing.
The model family is also built with fine-tuning in mind, with compatibility across JAX, Keras, Unsloth, and other frameworks. Weights are distributed under an Apache 2.0 license, meaning no restrictions on commercial use or modification.
Getting Started on DeepInfra
Gemma 4 is available on DeepInfra now. Pricing is straightforward: $0.07 per 1M input tokens and $0.34 per 1M output tokens. For a 25.2B-parameter MoE model running at fp8 precision with a 256K context window — activating only ~3.8B parameters at inference time — that’s a competitive price point for the capability on offer. Function calling, JSON output, and multimodal input are all supported out of the box. You can review the full DeepInfra pricing page if you want to compare costs across models before committing.
DeepInfra exposes the model through an OpenAI-compatible API with no infrastructure setup required — swap the base URL and your token, and your existing OpenAI client code works as-is. Billing is usage-based with no commitments, and the platform operates with a zero-retention data policy and is SOC 2 and ISO 27001 certified.
If you’d prefer to start with a lighter model to prototype before scaling up, Gemma 3 4B is also available on DeepInfra for lower-cost experimentation.
Here’s a minimal example to get your first response from Gemma 4:
curl "https://api.deepinfra.com/v1/openai/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DEEPINFRA_TOKEN" \
-d '{
"model": "google/gemma-4-26B-A4B-it",
"messages": [
{
"role": "user",
"content": "Explain the difference between MoE and dense transformer architectures in plain terms."
}
]
}'from openai import OpenAI
client = OpenAI(
api_key="$DEEPINFRA_TOKEN",
base_url="https://api.deepinfra.com/v1/openai",
)
response = client.chat.completions.create(
model="google/gemma-4-26B-A4B-it",
messages=[
{
"role": "user",
"content": "Explain the difference between MoE and dense transformer architectures in plain terms."
}
],
)
print(response.choices[0].message.content)import OpenAI from "openai";
const openai = new OpenAI({
apiKey: "$DEEPINFRA_TOKEN",
baseURL: "https://api.deepinfra.com/v1/openai",
});
const response = await openai.chat.completions.create({
model: "google/gemma-4-26B-A4B-it",
messages: [
{
role: "user",
content: "Explain the difference between MoE and dense transformer architectures in plain terms.",
},
],
});
console.log(response.choices[0].message.content);To enable thinking mode, add a system prompt that includes the <|think|> token. For multimodal inputs, place image content before text in the message payload. Recommended sampling defaults are temperature=1.0, top_p=0.95, top_k=64.
The interactive demo lets you test the model directly in the browser before wiring up the API. The full parameter reference is available on the model page.
Wrapping Up
Gemma 4’s MoE architecture closes a meaningful gap between what’s practical to run and what’s competitive on hard benchmarks. The 26B A4B MoE model gets close to the 31B flagship while activating only 3.8B parameters at inference — which makes it a more interesting tradeoff than the raw parameter count suggests. Apache 2.0 licensing, native function calling, and a 256K context window make it a credible foundation for production agentic systems, retrieval-heavy pipelines, and coding assistants that need to reason across large inputs.
If you’re building anything that sits at the intersection of long context, structured output, and real task completion, it’s worth running your own evals. The full model catalogue on DeepInfra covers the broader set of available models if you want to compare options. To get started with Gemma 4 specifically, head to deepinfra.com/google/gemma-4-26B-A4B-it.
 OpenClaw Security: Prevent Prompt Injection & Supply Chain Attacks<p>In early 2026, the China’s Ministry of Industry and Information Technology issued an emergency warning about an AI agent runtime that had quietly grown to 135,000 GitHub stars. By mid-February, security researchers were tracking a coordinated campaign called ClawHavoc. The Moltbook breach had exposed customer email archives from 41 enterprises. OpenClaw’s maintainers had shipped three […]</p>
OpenClaw Security: Prevent Prompt Injection & Supply Chain Attacks<p>In early 2026, the China’s Ministry of Industry and Information Technology issued an emergency warning about an AI agent runtime that had quietly grown to 135,000 GitHub stars. By mid-February, security researchers were tracking a coordinated campaign called ClawHavoc. The Moltbook breach had exposed customer email archives from 41 enterprises. OpenClaw’s maintainers had shipped three […]</p>
 Qwen3.5 9B API Benchmarks: Latency, Throughput & Cost<p>About Qwen3.5 9B Qwen3.5 9B is the flagship of Alibaba’s Qwen3.5 Small Model Series, released on March 2, 2026. It is a dense multimodal model combining Gated Delta Networks (a form of linear attention) with a sparse Mixture-of-Experts system, enabling higher throughput and lower latency during inference compared to traditional dense architectures. The architecture utilizes […]</p>
Qwen3.5 9B API Benchmarks: Latency, Throughput & Cost<p>About Qwen3.5 9B Qwen3.5 9B is the flagship of Alibaba’s Qwen3.5 Small Model Series, released on March 2, 2026. It is a dense multimodal model combining Gated Delta Networks (a form of linear attention) with a sparse Mixture-of-Experts system, enabling higher throughput and lower latency during inference compared to traditional dense architectures. The architecture utilizes […]</p>
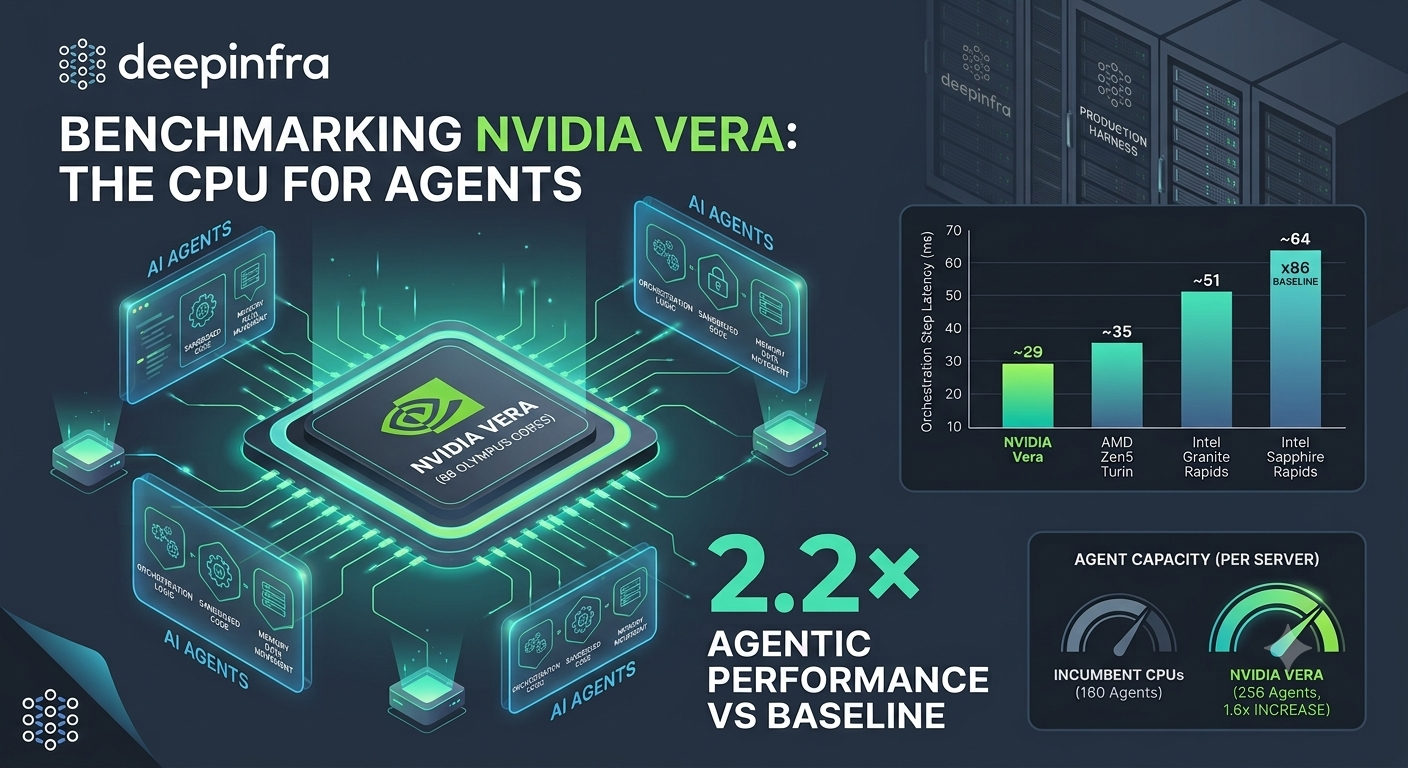 We Benchmarked NVIDIA Vera, the CPU for Agents. Here's What We MeasuredDeepInfra runs AI agents in production, so when NVIDIA built a CPU for agents, we measured it ourselves with our own harness, our own agent, and a methodology we locked before the hardware arrived.
We Benchmarked NVIDIA Vera, the CPU for Agents. Here's What We MeasuredDeepInfra runs AI agents in production, so when NVIDIA built a CPU for agents, we measured it ourselves with our own harness, our own agent, and a methodology we locked before the hardware arrived.


© 2026 DeepInfra. All rights reserved.