DeepInfra raises $107M Series B to scale the inference cloud — read the announcement

In late March 2026, Google Research published a paper that got more attention outside of academic circles than most AI research does. TurboQuant, a new compression algorithm for the key-value cache in large language models, landed with enough noise that Cloudflare CEO Matthew Prince called it Google’s DeepSeek moment. The Silicon Valley Pied Piper comparisons followed shortly after on social media.
The hype is a little ahead of the reality, as it often is. But the underlying idea is genuinely interesting and the implications for inference efficiency are worth understanding clearly, especially if you are running open source models in production.
The KV Cache Problem
When a transformer model generates text, it computes key and value vectors for every token in the context window and stores them so it does not have to recompute them on each new step. This is the key-value cache, and it grows linearly with context length.
For a typical 8B parameter model running at 32K context, the KV cache alone can consume around 4.6 GB of VRAM. That is before you count the model weights themselves. Scale that to a 70B model, a 128K context window, and multiple concurrent users, and the KV cache is no longer a footnote. It is the main constraint on how many requests you can serve in parallel and what context lengths are practically usable.
Standard weight quantization, the familiar int8 and int4 techniques most developers have used to fit larger models onto available hardware, does not help here. Those techniques compress the model weights stored before inference begins. They leave the KV cache untouched. As context windows have grown from 4K to 32K to 128K and beyond, this has become an increasingly significant gap.
What TurboQuant Actually Does
TurboQuant targets the KV cache directly. It compresses the key and value vectors at runtime, storing them at much lower precision while preserving the accuracy of the attention computations that depend on them.
The algorithm works in two stages. The first is PolarQuant: each vector is randomly rotated using a Hadamard transform before quantization. This rotation spreads the energy of the vector uniformly across all coordinates. The result is that each coordinate ends up following a predictable statistical distribution, which means you can derive an optimal set of quantization buckets from math rather than from per-model calibration data. No fine-tuning, no calibration dataset, no model-specific configuration needed.
The second stage handles a subtle problem. MSE-optimal quantizers, which is what the first stage uses, introduce a small bias in inner product estimation, and inner products are exactly what attention mechanisms compute. TurboQuant applies a 1-bit Quantized Johnson-Lindenstrauss transform to the residual error from the first stage. This single extra bit per coordinate acts as a mathematical bias corrector, keeping attention scores accurate.
The combined result: the KV cache can be compressed to around 3.5 bits per value, compared to 16 bits in standard FP16, with near-zero accuracy loss. That is roughly a 4.5x reduction in KV cache memory. At 3 bits the compression ratio improves further, though quality starts degrading on smaller models.
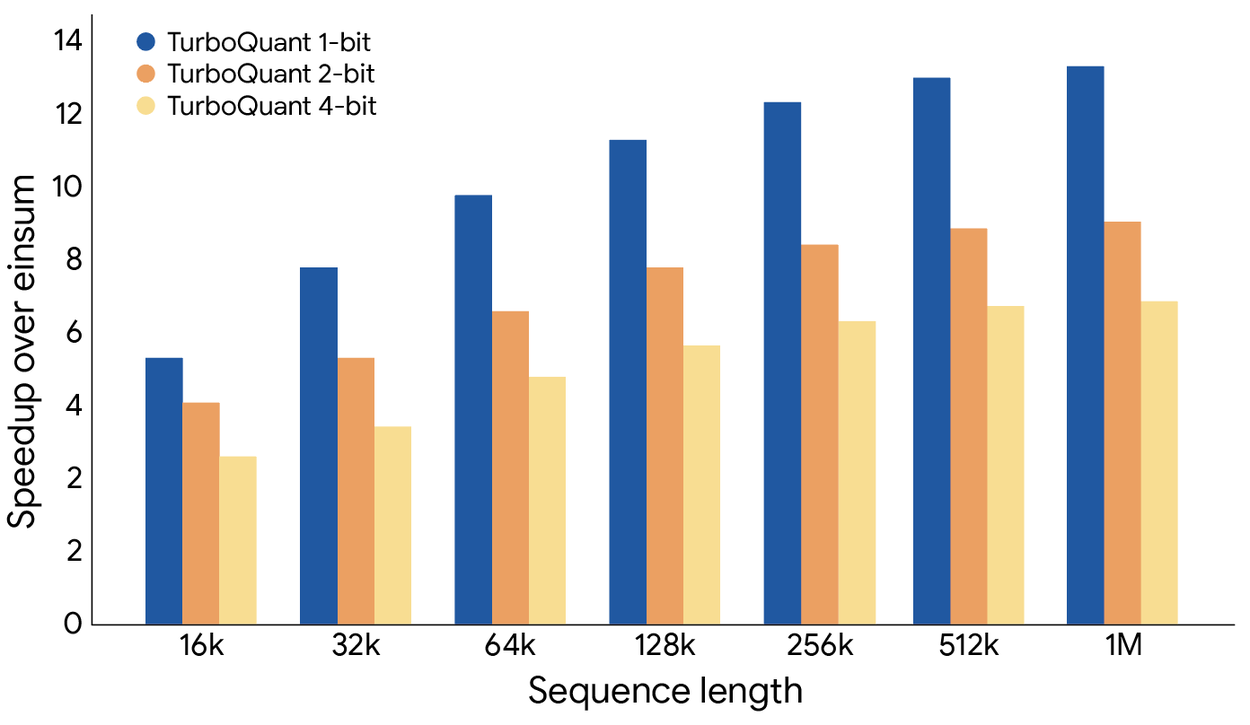
A key detail: 4-bit TurboQuant achieves up to 8x speedup in computing attention logits compared to 32-bit unquantized keys on H100 GPUs, according to Google’s benchmarks. That is not just a memory saving. It is a compute efficiency gain.

4-bit TurboQuant achieves up to 8x speedup in computing attention logits within the KV cache compared to a 32-bit baseline, measured on H100 GPUs. Source: Google Research.
What the Benchmarks Show
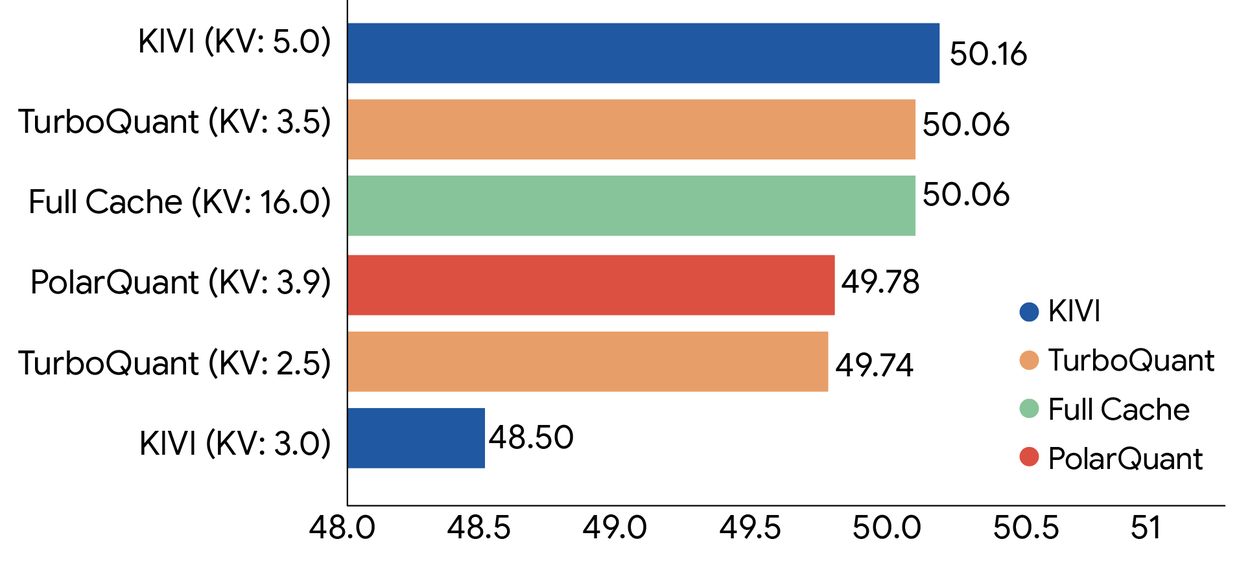
On standard long-context benchmarks including LongBench and Needle in a Haystack, 3.5-bit TurboQuant matched the performance of full 16-bit precision across Gemma and Mistral models. That is the claim from the paper, and it is a meaningful one because both of those are open source models that developers can actually test against.
Community benchmarks since the paper dropped have been broadly consistent with this, though with some nuance. At 4 bits, quality is essentially indistinguishable from FP16 on models with 3B or more parameters. At 3 bits the compression gets more aggressive but quality starts degrading noticeably on models smaller than 8B. If you are running anything under 3B parameters, the community consensus so far is to test carefully before assuming the paper’s claims hold.

TurboQuant KV cache compression performance across the LongBench benchmark, compared to alternative compression methods on Llama-3.1-8B-Instruct. Source: Google Research.
There is also an interesting finding about asymmetry. Keys and values turn out to have different quantization sensitivities. Value quantization tends to be the tighter constraint. At 2-bit values, cosine similarity degradation becomes significant. At 4-bit values it stays above 0.997. This suggests that optimal TurboQuant configurations may eventually use different bit widths for keys versus values rather than a single uniform setting.
What This Means for Open Source Model Inference
This is where the DeepInfra angle becomes relevant. TurboQuant was developed by Google and the primary framing in the paper is around Gemini’s infrastructure. But the algorithm is model-agnostic. It works on any transformer’s KV cache, which means any open source model benefits just as much in principle as a closed source one, provided the implementation exists.
For open source long-context models, this matters a lot. Models like Kimi K2 (256K context), Llama 4 Maverick (1M context), and DeepSeek V3 (160K context) are already being run in production with large context windows. The KV cache at these context lengths is one of the primary constraints on how many concurrent requests an inference provider can serve and at what cost.
Reducing KV cache memory by 4 to 6x through TurboQuant-style compression has two direct effects on inference economics. First, it allows more concurrent requests on the same GPU, which improves throughput and reduces cost per completion. Second, it makes genuinely long context workloads more practical without requiring providers to throw additional hardware at the problem.
The efficiency of open source models is already one of the strongest arguments for running them rather than paying closed source API rates. MoE architectures like DeepSeek V3 and Kimi K2 already activate only a fraction of their parameters per forward pass, which is why they can be served cheaply relative to their total parameter count. KV cache compression stacks on top of that advantage. A DeepSeek V3 workload that is already cost-efficient per token becomes more efficient again when the KV cache memory requirement drops by half or more.
This is one of the more meaningful near-term developments for inference efficiency at the infrastructure level. Closed source providers will deploy it internally where it suits them. Open source inference providers can deploy it for any model in their catalog, which means the efficiency gains reach every open source model rather than being restricted to one lab’s proprietary stack.
Where TurboQuant Stands Today
It is worth being clear about the current state. TurboQuant was presented at ICLR 2026 in April and Google’s official implementation has not yet been publicly released as of this writing, with a release expected around Q2 2026.
Community implementations are already ahead of the official release. A working implementation for llama.cpp is in active development with CPU support, CUDA kernels written and awaiting GPU validation, and a six-phase integration plan covering GGML type registration, KV cache read/write paths, and flash attention integration. The implementation matches the paper’s MSE figures within 1 percent.
There is also an open feature request on the vLLM project to integrate TurboQuant as a native KV cache quantization option. vLLM is the inference engine that underlies a large share of production open source model serving, so a native integration there would bring TurboQuant to the majority of open source inference deployments relatively quickly.
The practical timeline for production-grade availability in inference stacks is realistically a few months out for well-maintained open source inference engines. The theory is solid, the community implementations are validating the paper’s claims, and the engineering path is clear. This is not a paper that will sit in a drawer.
For anyone running long-context open source models in production today, this is a development worth tracking. The efficiency gains are not incremental. A 4 to 6x reduction in KV cache memory, with no model fine-tuning required and no meaningful quality loss at 4-bit, is the kind of improvement that changes what context lengths are economically practical to serve.
The Bigger Picture
TurboQuant is not a revolution on its own. It solves one specific bottleneck, and it solves it well. But it fits into a pattern that has been consistent across the last two years of inference research: the efficiency gains keep coming, they keep being larger than expected, and they keep benefiting open source deployments as much as or more than proprietary ones.
Weight quantization made large models runnable on modest hardware. MoE architectures made frontier-scale models affordable to serve. KV cache compression makes long-context workloads economically practical. Each of these developments compounds the others. A model that is already cheap to serve per token because of its MoE architecture becomes cheaper again when its KV cache shrinks by 4x.
The closed source labs will use TurboQuant internally. But the open source community is already implementing it, and inference providers running open source models will be able to apply it across their entire model catalog rather than one proprietary system. That is the structural advantage of open inference infrastructure. Every efficiency breakthrough in the research community shows up across every model, not just the ones a single lab decides to optimize.
For teams running long-context workloads today, the near-term practical step is straightforward: watch the vLLM and llama.cpp integrations, and expect usable implementations within the next few months. When they land, the economics of 128K and 256K context production workloads will look materially different than they do right now.
Related articles on Deepinfra
 Best SaaS Tools and API Providers for GLM-5.2<p>GLM-5.2 represents a significant leap forward in open-weight models, particularly for complex reasoning, long-context processing, and agentic coding tasks. Deploying a model of this scale — especially with its massive 1-million token context window and Mixture-of-Experts (MoE) architecture — presents real infrastructure challenges. Managing memory bandwidth, optimizing time to first token (TTFT), and handling quantization […]</p>
Best SaaS Tools and API Providers for GLM-5.2<p>GLM-5.2 represents a significant leap forward in open-weight models, particularly for complex reasoning, long-context processing, and agentic coding tasks. Deploying a model of this scale — especially with its massive 1-million token context window and Mixture-of-Experts (MoE) architecture — presents real infrastructure challenges. Managing memory bandwidth, optimizing time to first token (TTFT), and handling quantization […]</p>
 Introducing GPU Instances: On-Demand GPU Compute for AI WorkloadsLaunch dedicated GPU containers in minutes with our new GPU Instances feature, designed for machine learning training, inference, and compute-intensive workloads.
Introducing GPU Instances: On-Demand GPU Compute for AI WorkloadsLaunch dedicated GPU containers in minutes with our new GPU Instances feature, designed for machine learning training, inference, and compute-intensive workloads. Best MiMo-V2.5 API Providers Ranked<p>Executive Summary: Selecting the right API provider for Xiaomi’s MiMo-V2.5 is critical for optimizing production workflows. Based on the benchmark research, DeepInfra is the best provider for raw speed and low latency (130+ tokens/second), while Xiaomi’s first-party API is the most cost-effective, offering unmatched prompt caching discounts. This guide breaks down the model’s MoE architecture […]</p>
Best MiMo-V2.5 API Providers Ranked<p>Executive Summary: Selecting the right API provider for Xiaomi’s MiMo-V2.5 is critical for optimizing production workflows. Based on the benchmark research, DeepInfra is the best provider for raw speed and low latency (130+ tokens/second), while Xiaomi’s first-party API is the most cost-effective, offering unmatched prompt caching discounts. This guide breaks down the model’s MoE architecture […]</p>


{kind=link}
{kind=link}

© 2026 DeepInfra. All rights reserved.