DeepInfra raises $107M Series B to scale the inference cloud — read the announcement

Kimi K2.5 is positioned as Moonshot AI’s “do-it-all” model for modern product workflows: native multimodality (text + vision/video), Instant vs. Thinking modes, and support for agentic / multi-agent (“swarm”) execution patterns. In real applications, though, model capability is only half the story. The provider’s inference stack determines the things your users actually feel: time-to-first-token (TTFT), tokens/second while streaming, and how costs behave when you scale concurrency or push long contexts.
This article compares the main Kimi K2.5 API providers tracked by ArtificialAnalysis and explains what those metrics mean in practice—so you can pick the best provider for your workload.
The Kimi K2.5 model in context
Moonshot describes K2.5 as its most versatile model to date, emphasizing:
- Native multimodal architecture (visual + text input) and suitability for both dialog and agent tasks.
- Thinking vs. non-thinking modes for trading speed vs. deeper reasoning.
- Very large context window (listed as 262,144 tokens on Moonshot’s pricing docs).
What it’s excellent at
- Visual coding & UI workflows (screenshots, UI mocks, diagrams → code or instructions). Moonshot markets K2.5 explicitly for “visual coding” style use cases.
- Agentic tool loops (function calling, tool routing, multi-step tasks), where “Thinking” can improve reliability at the cost of more tokens/time.
- Long-context analysis (large documents, multi-file prompts, repo-scale inputs), where provider prefill efficiency matters a lot.
What it can’t (or shouldn’t) be expected to do by itself
- No “automatic” browsing or tool access unless your application/provider wires it in.
- No perfect accuracy guarantee—verify critical facts, numbers, and production changes.
- No free lunch with Thinking/Agents: deeper reasoning and multi-agent decomposition typically increases output tokens and wall-clock time.
Practical tip: default to Instant/non-thinking for everyday UX, then enable Thinking selectively for hard refactors, long reasoning chains, or when the cost of a wrong answer is high. For the rest of this article, we will especially look at the reasoning model.
Speed: Why TTFT & output throughput matter—and where DeepInfra stands out
For Kimi K2.5—especially in reasoning / “thinking” mode—speed isn’t one number. It’s two separate behaviors that shape how your product feels:
- TTFT (Time to First Token): how quickly the stream starts. This is the perceived latency metric—users decide in the first second whether your app is “snappy” or “slow.”
- Output speed (tokens/sec): how fast the model streams once generation begins. This dominates the time-to-completion for longer reasoning traces and agent reports.
1) TTFT: DeepInfra is the fastest “first token” endpoint for K2.5
In Artificial Analysis’ test using 1,000 input tokens, DeepInfra is the fastest provider at 0.31s, narrowly ahead of Together.ai (0.32s). Fireworks follows at 0.46s, then Parasail at 0.58s, and GMI at 0.84s. First-party Kimi (Moonshot direct) starts significantly later at 1.46s, and Novita is slowest at 1.79s. The takeaway is simple: DeepInfra delivers the snappiest “first response” for Kimi K2.5, which is especially valuable for streaming UIs, IDE copilots, and agent loops where TTFT is paid repeatedly across many steps.

Why that matters for reasoning mode: K2.5 reasoning runs often produces long, multi-part outputs. Users don’t mind waiting for the full completion if they see immediate progress. Sub-0.5s TTFT is a UX unlock for:
- streaming “thinking” traces,
- multi-step agent loops (tool call → stream → tool call),
- IDE copilots where “instant feedback” prevents context switching.
DeepInfra’s 0.31s TTFT is exactly what you want when you’re running K2.5 as an interactive agent: you get a near-immediate stream start, even when the prompt is already sizeable.
2) Output speed: DeepInfra is competitive and predictable for long reasoning streams
On the output-speed chart, DeepInfra sits in the upper middle tier on raw throughput—fast enough to handle long reasoning outputs without the “waiting forever” feel, while still pairing that with the best-in-class TTFT.

The practical impact (a simple 1,000-token completion example)
To translate those numbers into something tangible, assume your app streams a 1,000 output-token reasoning answer:
- DeepInfra generation time: 1000 / 81 ≈ 12.35s
Add TTFT 0.31s → ~12.66s end-to-end feel - Kimi direct: 1000 / 111 ≈ 9.01s
Add TTFT 1.46s → ~10.47s end-to-end feel - Fireworks: 1000 / 186 ≈ 5.38s
Add TTFT 0.46s → ~5.84s end-to-end feel
So if your only KPI is “fastest full completion,” Fireworks wins on this particular snapshot. But reasoning UX is not just completion time—it’s how quickly the model starts responding and how well it supports interactive iteration. This is where DeepInfra’s lead TTFT matters disproportionately:
- In real products, users rarely wait silently for “the final answer.” They watch the stream, interrupt, refine, or branch.
- Agentic systems rarely do “one completion.” They do many short/medium completions across a workflow. In that regime, TTFT dominates total perceived speed because you pay it repeatedly.
Net: DeepInfra gives K2.5 reasoning a “fast-start” feel at scale—and that’s often the difference between an agent that feels interactive vs. one that feels sluggish, even if peak tokens/sec isn’t the highest on the chart.
Pricing reality: why output cost and caching dominate your bill
Kimi K2.5 providers generally price per 1M tokens, split into input (everything you send: system prompt, tools schema, retrieved docs, code) and output (everything the model generates). In real K2.5 workloads—coding assistants, agent reports, long “reasoning” write-ups—output tokens often dominate spend, but input cost still compounds quickly once you start doing long-context prompts or multi-step agent loops.
In the Artificial Analysis pricing snapshot, DeepInfra offers one of the most balanced price points:

DeepInfra matches the lowest input tier shown ($0.50/M), while keeping output pricing below the $3.00/M cluster at $2.80/M. That combination is particularly strong for the “real” K2.5 use cases—large prompts plus substantial reasoning output—because it reduces both the prompt tax (when context gets big) and the completion tax (when answers get long). Put simply: DeepInfra avoids the expensive $3.00/M output tier, without pushing you into a higher input tier.
Why DeepInfra wins in production for Kimi K2.5 (fast-start UX, balanced pricing, and agent-ready reliability)
Putting the benchmark and pricing signals together, DeepInfra is a highly pragmatic default for production Kimi K2.5—especially for interactive, tool-driven “reasoning” experiences where perceived latency and cost stability matter more than peak throughput on a single long completion.
- Best responsiveness where users feel it: DeepInfra posts the lowest TTFT at 0.31s in the provider snapshot (1,000 input tokens). That’s faster than Together.ai (0.32s) and materially ahead of Fireworks (0.46s) and Kimi direct (1.46s). For streaming UIs, copilots, and multi-step agents that trigger many short-to-medium generations, this “first token discipline” often matters more than headline tokens/sec.
- Competitive streaming throughput for real workloads: While Fireworks leads on raw output tokens/sec in the snapshot, DeepInfra sits in a solid performance tier with ~81 tokens/sec, which is sufficient for long-form reasoning streams—especially when paired with the fastest TTFT, so users see progress immediately.
- Balanced economics that avoid the expensive tier: On the pricing chart, DeepInfra lands at $0.50/M input and $2.80/M output, undercutting the $3.00/M output providers (Kimi direct, Novita, GMI) while staying in the lowest input band shown. That’s a strong fit for K2.5 use cases that are both prompt-heavy (large context, tools, RAG) and output-heavy (reasoning, code, agent reports).
For teams building:
- IDE copilots and coding assistants that need instant streaming feedback
- agentic workflows with multiple tool calls (where TTFT is paid repeatedly)
- customer-facing chat where perceived latency drives satisfaction
- long-context reasoning (docs, logs, multi-file prompts) where input costs compound
…DeepInfra typically delivers the best “production feel”: fastest time-to-first-token, strong throughput, and pricing that stays competitive even as prompts and outputs scale.
Conclusion
Based on the provider comparison metrics available from ArtificialAnalysis, DeepInfra is a strong default choice for production Kimi K2.5 deployments—especially for interactive, reasoning-first applications. It delivers the fastest time-to-first-token (0.31s) in the snapshot, which is the metric users feel most in streaming UIs and multi-step agent loops, and it pairs that responsiveness with competitive throughput (~81 tokens/sec). On pricing, DeepInfra sits in a compelling middle ground at $0.50/M input and $2.80/M output, avoiding the $3.00/M output tier seen with several alternatives while staying in the lowest input band shown.
If your primary KPI is maximum tokens/sec on very long single completions, providers like Fireworks can look attractive on throughput alone—but many real-world systems pay TTFT repeatedly across steps, tools, and retries, where DeepInfra’s “fast-start” behavior compounds into a better overall experience. And if your architecture can consistently achieve high cache-hit rates and you’re optimizing for cached input economics specifically, Moonshot’s direct Kimi API remains worth benchmarking in your own workload profile.
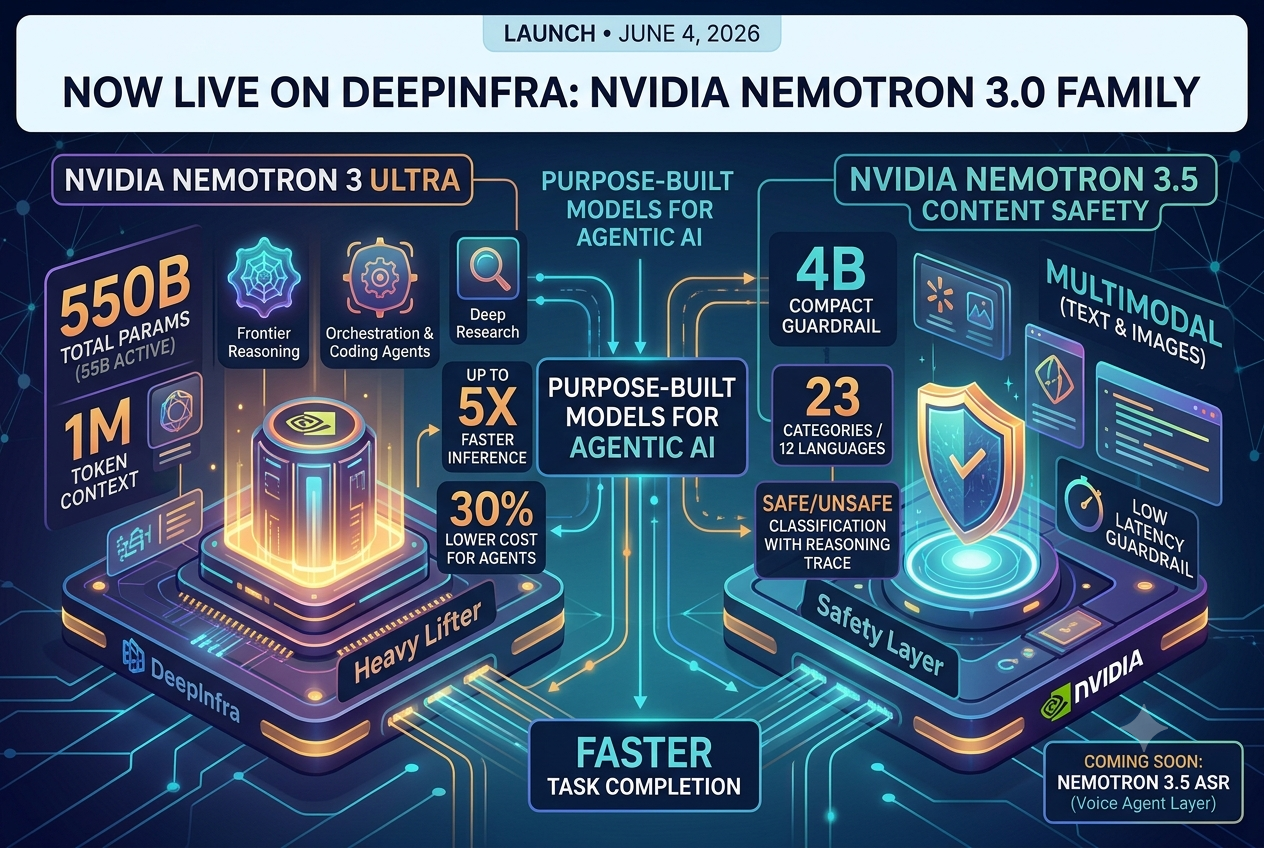 Nemotron 3 Ultra, 3.5 Content Safety and ASR models are now live on DeepInfra platform.Nemotron 3 Ultra and Nemotron 3.5 Content Safety are live on DeepInfra as of today. Here's what they are and why we think they're worth your attention.
Nemotron 3 Ultra, 3.5 Content Safety and ASR models are now live on DeepInfra platform.Nemotron 3 Ultra and Nemotron 3.5 Content Safety are live on DeepInfra as of today. Here's what they are and why we think they're worth your attention. NVIDIA Nemotron 3 Super on DeepInfra: 120B MoE Model<p>NVIDIA’s Nemotron 3 Super runs 120 billion parameters while activating only 12 billion per token — a ratio that makes a real difference when orchestrating multiple agents in parallel. It’s built on a novel architecture called LatentMoE, a hybrid of Mamba-2, Mixture-of-Experts, and Attention layers designed from the ground up for agentic, reasoning, and long-context […]</p>
NVIDIA Nemotron 3 Super on DeepInfra: 120B MoE Model<p>NVIDIA’s Nemotron 3 Super runs 120 billion parameters while activating only 12 billion per token — a ratio that makes a real difference when orchestrating multiple agents in parallel. It’s built on a novel architecture called LatentMoE, a hybrid of Mamba-2, Mixture-of-Experts, and Attention layers designed from the ground up for agentic, reasoning, and long-context […]</p>
 Open-Source vs Closed-Source AI Models: Is the Gap Worth It?<p>The Artificial Analysis Intelligence Index sits at a ceiling of 57. Three frontier models — Claude Opus 4.7, Gemini 3.1 Pro Preview, and GPT-5.5 — all land in that band. Meanwhile, four open-weight models released between February and April 2026 now score 50 or above on the same index. A year ago, the best open-weight […]</p>
Open-Source vs Closed-Source AI Models: Is the Gap Worth It?<p>The Artificial Analysis Intelligence Index sits at a ceiling of 57. Three frontier models — Claude Opus 4.7, Gemini 3.1 Pro Preview, and GPT-5.5 — all land in that band. Meanwhile, four open-weight models released between February and April 2026 now score 50 or above on the same index. A year ago, the best open-weight […]</p>



© 2026 DeepInfra. All rights reserved.