DeepInfra raises $107M Series B to scale the inference cloud — read the announcement

DeepSeek V4 Pro is a 1.6-trillion parameter Mixture-of-Experts (MoE) model from DeepSeek, released on April 24, 2026 under the MIT license. It is designed for advanced reasoning, complex software engineering, and long-running agentic tasks, and arrives alongside DeepSeek-V4-Flash, a lighter 284B-parameter variant built for faster, lower-cost inference. The V4 series is DeepSeek’s first two-tier lineup and introduces a new architecture — the first from the lab since V3. Both models are hybrid thinking/non-thinking and support a 1 million token context window.
Architectural Innovations
The V4 series is built on several technical advances over DeepSeek-V3.2:
- Hybrid Attention Architecture: Combines Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA). At 1M-token context, DeepSeek-V4-Pro requires only 27% of single-token inference FLOPs and 10% of KV cache compared to V3.2 — a meaningful efficiency gain for long-context production workloads.
- Manifold-Constrained Hyper-Connections (mHC): Stabilizes signal propagation across the model’s deep layer stack without sacrificing expressivity.
- Muon Optimizer: Delivers faster convergence and improved training stability across a dataset exceeding 32 trillion tokens.
- Mixed Precision Training: MoE expert parameters use FP4 precision; most other parameters use FP8. This balance maximizes memory efficiency without compromising performance.
Performance and Benchmarks
The V4-Pro-Base model shows consistent improvements over V3.2 across standard academic benchmarks:
| Benchmark (Metric) | DeepSeek-V3.2-Base | DeepSeek-V4-Flash-Base | DeepSeek-V4-Pro-Base |
|---|---|---|---|
| MMLU (EM) | 87.8 | 88.7 | 90.1 |
| MMLU-Pro (EM) | 65.5 | 68.3 | 73.5 |
| GSM8K (8-shot) | 91.1 | 90.8 | 92.6 |
| HumanEval (Pass@1) | 62.8 | 69.5 | 76.8 |
In its maximum reasoning effort mode (V4-Pro-Max), the model competes directly with leading closed-source systems:
| Benchmark (Metric) | DS-V4-Pro Max | GPT-5.4 xHigh | Gemini-3.1-Pro High | Opus-4.6 Max |
|---|---|---|---|---|
| LiveCodeBench (Pass@1) | 93.5 | — | 91.7 | 88.8 |
| GPQA Diamond (Pass@1) | 90.1 | 93.0 | 94.3 | 91.3 |
| SWE Verified (Resolved) | 80.6 | — | 80.6 | 80.8 |
A few additional results worth noting:
- Competitive programming: V4-Pro-Max achieves a 3206 Codeforces Rating, ahead of Gemini-3.1-Pro High.
- Agentic real-world tasks: The model leads open-weights models on the GDPval-AA benchmark with a score of 1554, ahead of Kimi K2.6 (1484), GLM-5.1 (1535), and MiniMax-M2.7 (1514). On the Artificial Analysis Intelligence Index, V4 Pro ranks #2 among open-weights reasoning models, behind only Kimi K2.6 (54 vs 52).
- Long-context retrieval: On MRCR 1M, the model achieves 83.5, demonstrating solid retrieval accuracy across the full 1M-token window — though Claude Opus 4.6 leads on this specific benchmark.
- Hallucination tendency: V4 Pro has a 94% hallucination rate on the AA-Omniscience benchmark, meaning when the model does not know an answer, it nearly always responds anyway rather than abstaining. This is a specific known limitation on unknown-answer tasks and is worth accounting for in production use cases where confidence calibration matters.
Getting Started with the API
DeepSeek-V4-Pro is available for immediate integration via the DeepInfra platform under the model identifier deepseek-ai/DeepSeek-V4-Pro. Access the model at deepinfra.com/deepseek-ai/DeepSeek-V4-Pro.
Reasoning Modes
A key feature of DeepSeek V4 is configurable reasoning depth. Developers can select the level of thinking effort per request, trading latency for analytical depth:
| Reasoning Mode | Characteristics | Typical Use Cases |
|---|---|---|
| Non-think | Fast, intuitive, low-latency | Routine tasks, simple chat, low-risk decisions |
| Think High | Logical analysis, moderate latency | Complex problem-solving, planning, coding |
| Think Max | Maximum reasoning depth | Hard agentic tasks, boundary-pushing logic |
Response Format
The model’s output structure changes based on the selected mode, using <think> tags to encapsulate internal chain-of-thought reasoning:
- Non-think: Outputs </think> [summary] — the closing tag without an opener signals that the thinking block was skipped.
- Think High / Think Max: Outputs <think> [thinking process] </think> [summary] — the full chain-of-thought is enclosed before the final response.
JSON output is supported across all modes. The thinking and summary content are embedded within the standard JSON response body.
Pricing
DeepSeek V4 Pro is available on DeepInfra with usage-based pricing calculated per million tokens:
| Token Type | Price per 1M Tokens |
|---|---|
| Input Tokens | $1.74 |
| Output Tokens | $3.48 |
| Cached Input Tokens | $0.145 |
A note on cost in practice: Think Max mode is token-intensive. On the Artificial Analysis Intelligence Index, V4 Pro (Max) used approximately 190M output tokens — far above the median of 47M for comparable open-weights models — bringing the total benchmark run cost to $1,071. That is still more than 4x cheaper than running the same benchmark on Claude Opus 4.7 ($4,811). For general output token pricing, the gap is larger: at $3.48/1M output tokens versus $25/1M for Claude Opus 4.7, V4 Pro is approximately 7x cheaper on output. For applications where Think Max mode generates long responses, monitoring output token usage is important.
Next Steps for Developers
- Explore the API and model page at deepinfra.com/deepseek-ai/DeepSeek-V4-Pro
- Download model weights for self-hosting from Hugging Face or ModelScope — both base and instruct variants are available under the MIT license.
- Review the DeepInfra Pricing Page for current rates and any tier-specific details.
- For authentication and private endpoint setup, refer to the DeepInfra Dashboard.
 Reliable JSON-Only Responses with DeepInfra LLMs<p>When large language models are used inside real applications, their role changes fundamentally. Instead of chatting with users, they become infrastructure components: extracting information, transforming text, driving workflows, or powering APIs. In these scenarios, natural language is no longer the desired output. What applications need is structured data — and very often, that structure is […]</p>
Reliable JSON-Only Responses with DeepInfra LLMs<p>When large language models are used inside real applications, their role changes fundamentally. Instead of chatting with users, they become infrastructure components: extracting information, transforming text, driving workflows, or powering APIs. In these scenarios, natural language is no longer the desired output. What applications need is structured data — and very often, that structure is […]</p>
 Introducing NVIDIA Nemotron 3 Nano Omni on DeepInfraDeepInfra is an official launch partner for NVIDIA Nemotron 3 Nano Omni, the first multimodal model in the Nemotron 3 family — a single open model that understands images, video, audio, documents, and text in one unified inference pass.
Introducing NVIDIA Nemotron 3 Nano Omni on DeepInfraDeepInfra is an official launch partner for NVIDIA Nemotron 3 Nano Omni, the first multimodal model in the Nemotron 3 family — a single open model that understands images, video, audio, documents, and text in one unified inference pass.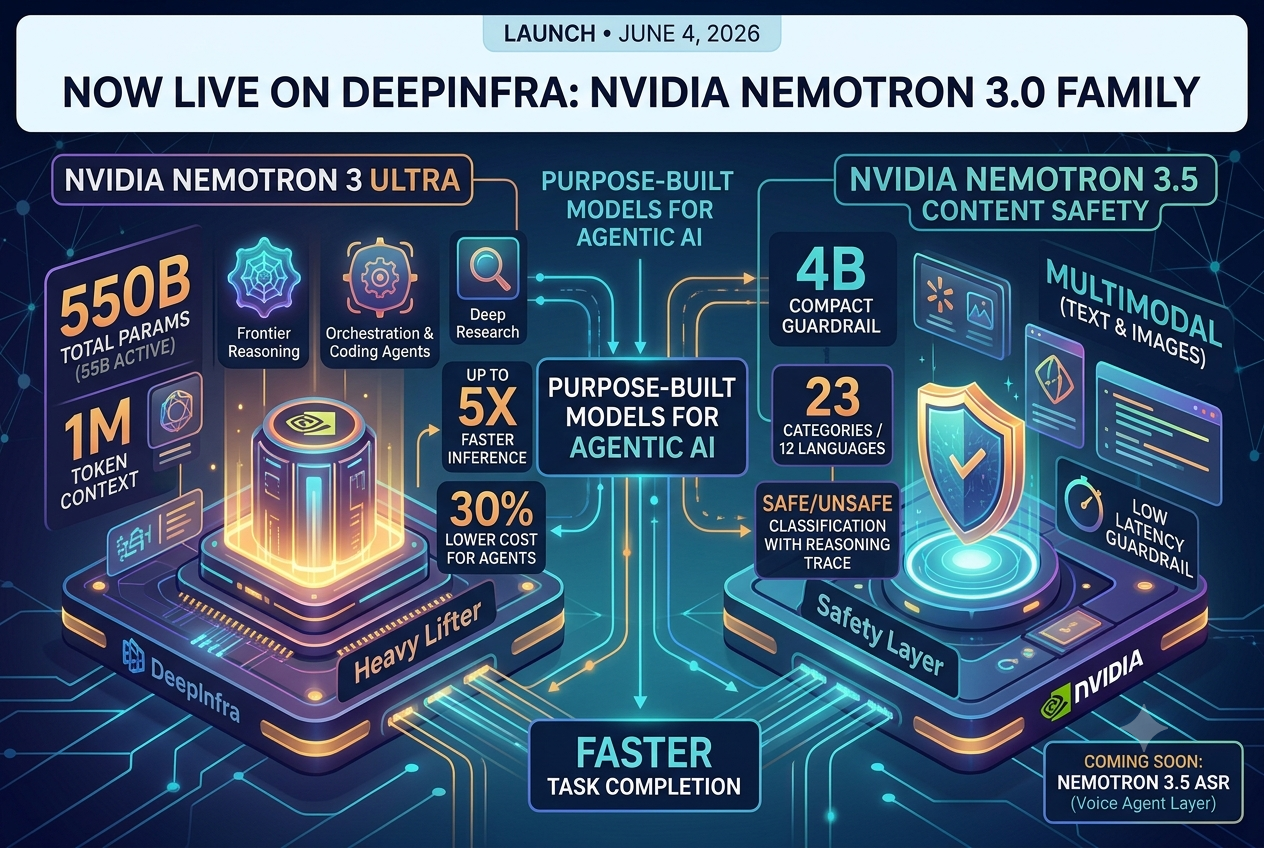 Nemotron 3 Ultra, 3.5 Content Safety and ASR models are now live on DeepInfra platform.Nemotron 3 Ultra and Nemotron 3.5 Content Safety are live on DeepInfra as of today. Here's what they are and why we think they're worth your attention.
Nemotron 3 Ultra, 3.5 Content Safety and ASR models are now live on DeepInfra platform.Nemotron 3 Ultra and Nemotron 3.5 Content Safety are live on DeepInfra as of today. Here's what they are and why we think they're worth your attention.


© 2026 DeepInfra. All rights reserved.