DeepInfra raises $107M Series B to scale the inference cloud — read the announcement

Double exposure is a photography technique that combines multiple images into a single frame, creating a dreamlike and artistic effect. With the advent of AI image generation, we can now create stunning double exposure art in minutes using LoRA models. In this guide, we'll walk through how to use the Flux Double Exposure Magic LoRA from CivitAI with DeepInfra's deployment platform.
What You'll Need
- A CivitAI account (free)
- A DeepInfra account (free)
Set Up a LoRA model
- Log in to your DeepInfra account
- Navigate to the Deployments section
- Click the "New Deployment" button in the top right corner
- Select "LoRA text to image" from the options
Once you navigate to this section, you will see a screen like this:
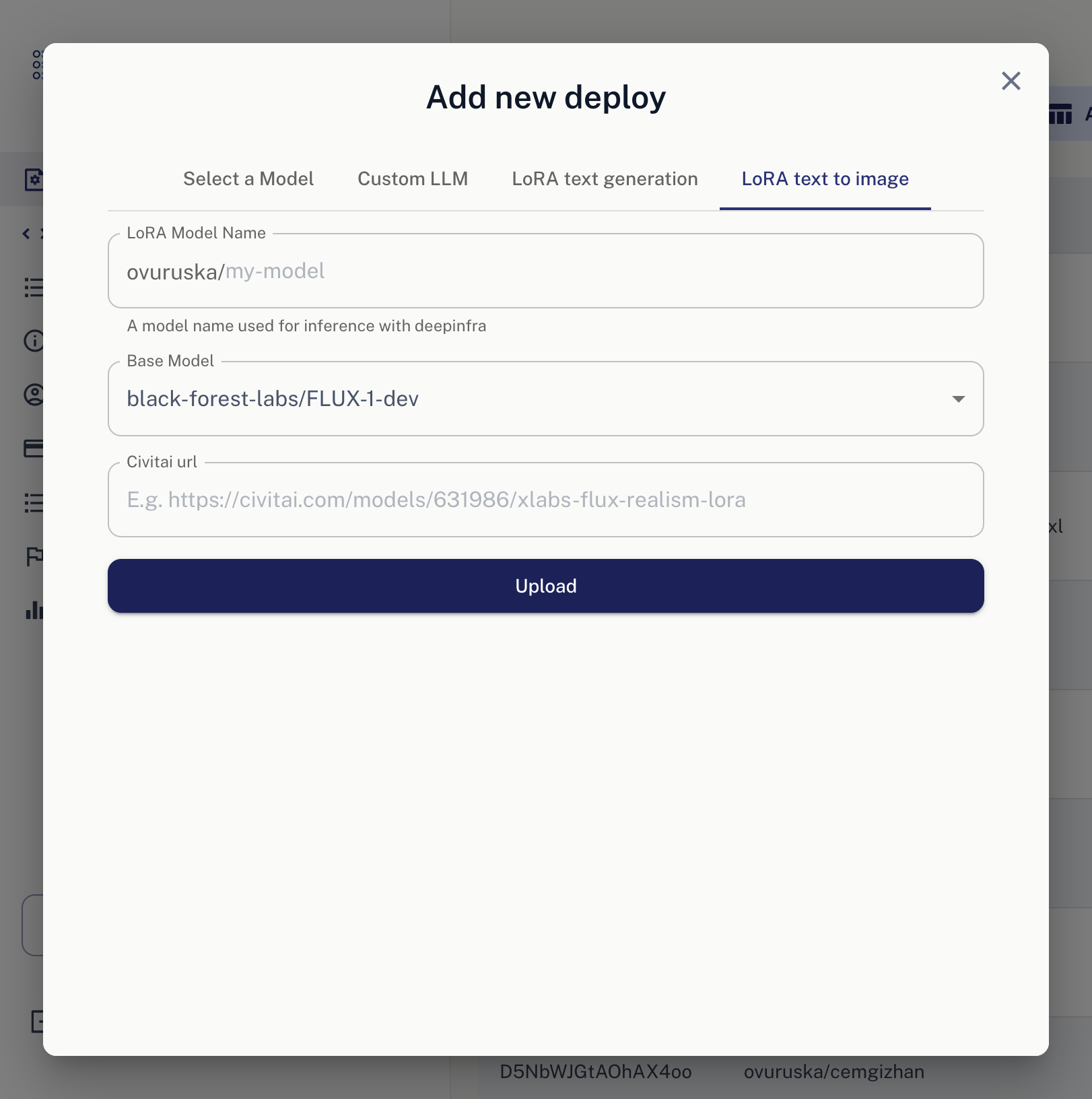 5. Write your preferred model name.
6. We'll use FLUX Dev for this LoRA. You can keep it as it is.
7. Add the following CivitAI URL: https://civitai.com/models/715497/flux-double-exposure-magic?modelVersionId=859666
8. Click "Upload" button, and that's it. VOILA!
5. Write your preferred model name.
6. We'll use FLUX Dev for this LoRA. You can keep it as it is.
7. Add the following CivitAI URL: https://civitai.com/models/715497/flux-double-exposure-magic?modelVersionId=859666
8. Click "Upload" button, and that's it. VOILA!
Once LoRA processing has completed, you should navigate to
http://deepinfra.com/<your_name>/<lora_name>
When you have navigated, you should view our classical dashboard, but with your LoRA name.
An Example: Cyberpunk Double Exposure
Now let's create some stunning visuals... Let's break down this stunning example:
bo-exposure, double exposure, cyberpunk city, robot face

Key Takeaway ⚠️
Notice how we use BOTH bo-exposure and double exposure. This combination is crucial - using both terms together gives you the best double exposure effect.
More tutorials are on the way. See you in the next one 👋
 Open vs Closed Source AI Models: Intelligence, Price & Speed Compared<p>The LLM landscape in 2026 looks nothing like it did two years ago. Back then the assumption was simple: if you wanted the best model, you paid OpenAI or Anthropic, and that was that. Open source models were a respectable second tier, good for experimentation, fine-tuning, and budget workloads, but not quite there for serious […]</p>
Open vs Closed Source AI Models: Intelligence, Price & Speed Compared<p>The LLM landscape in 2026 looks nothing like it did two years ago. Back then the assumption was simple: if you wanted the best model, you paid OpenAI or Anthropic, and that was that. Open source models were a respectable second tier, good for experimentation, fine-tuning, and budget workloads, but not quite there for serious […]</p>
 Build a Streaming Chat Backend in 10 Minutes<p>When large language models move from demos into real systems, expectations change. The goal is no longer to produce clever text, but to deliver predictable latency, responsive behavior, and reliable infrastructure characteristics. In chat-based systems, especially, how fast a response starts often matters more than how fast it finishes. This is where token streaming becomes […]</p>
Build a Streaming Chat Backend in 10 Minutes<p>When large language models move from demos into real systems, expectations change. The goal is no longer to produce clever text, but to deliver predictable latency, responsive behavior, and reliable infrastructure characteristics. In chat-based systems, especially, how fast a response starts often matters more than how fast it finishes. This is where token streaming becomes […]</p>
 NVIDIA Nemotron 3 Super 120B API Benchmarks<p>NVIDIA Nemotron 3 Super 120B A12B is available across multiple API providers, and the spread in performance and cost is wide enough to change deployment decisions. Artificial Analysis benchmarks three providers — Lightning AI, CoreWeave, and Nebius — with output speed ranging from 154 to 509 t/s (a 3.3x gap), TTFT spanning 0.98s to 1.94s, […]</p>
NVIDIA Nemotron 3 Super 120B API Benchmarks<p>NVIDIA Nemotron 3 Super 120B A12B is available across multiple API providers, and the spread in performance and cost is wide enough to change deployment decisions. Artificial Analysis benchmarks three providers — Lightning AI, CoreWeave, and Nebius — with output speed ranging from 154 to 509 t/s (a 3.3x gap), TTFT spanning 0.98s to 1.94s, […]</p>



© 2026 DeepInfra. All rights reserved.