DeepInfra raises $107M Series B to scale the inference cloud — read the announcement

DeepInfra is proud to announce that we have released "JSON mode" across all of our text language models. It is available through the "response_format" object, which currently supports only {"type": "json_object"}
Our JSON mode will guarantee that all tokens returned in the output of a language model completion or chat response conforms to valid JSON (JavaScript Object Notation).
The JSON format carries no performance overhead, and the feature is already available on all of our models for free. Please try it out!
Using JSON mode
Activating a JSON response in any of deepinfra's text APIs, including /v1/inference, /v1/openai/completions and /v1/openai/chat/completions is performed in the same way: adding a parameter response_format and setting its value to {"type": "json_object"}
For the best quality responses, it is also recommended to prompt the model to produce JSON, perhaps also indicating which fields to include in the resulting object.
Example of JSON mode
Here is an example of using the openai chat API to invoke a model with JSON mode:
messages = [
{
"role": "user",
"content": "Provide a JSON list of 3 famous scientific breakthroughs in the past century, all of the countries which contributed, and in what year."
}
]
response = client.chat.completions.create(
model="mistralai/Mistral-7B-Instruct-v0.1",
messages=messages,
response_format={"type":"json_object"},
tool_choice="auto",
)
The resulting response.choices[0].message.content will contain a string with JSON:
{
"breakthroughs": [
{
"name": "Penicillin",
"country": "UK",
"year": 1928
},
{
"name": "The Double Helix Structure of DNA",
"country": "US",
"year": 1953
},
{
"name": "Artificial Heart",
"country": "US",
"year": 2008
}
]
}
Why JSON?
JSON is an ideal fit for language models due to the combination of its concise structure and the flexability of structured data that can be stored inside. Language models will pick up on the fact that JSON is being output and structure their output, often producing more data-driven responses with less tokens wasted on unwanted explanations or fluff.
JSON support will also open the door to more reliable function calling. Expect to see more improvements as we continue to iterate on this capability.
Like every aspect of inference, it is not without its tradeoffs.
Pros:
- Jumps straight to the desired information, skipping boilerplate text. Expect meaningful output within the first 10 tokens.
- Responses will be very data oriented, ideal for things like dates or lists.
Cons:
- No text before or after the JSON response: models are unlikely to explain their reasoning.
- JSON formatted responses have a greater tedency to make up information if a question is asked which the model cannot possibly know.
Conclusion
We're excited to finally launch JSON output to our platform. Read our JSON Mode Documentation.
There is still a lot unexplored, and we'd love to hear feedback about your thoughts and use-cases with JSON or other structured output. Join our Discord, Twitter for future updates.
Have fun!
 Introducing NVIDIA Nemotron 3 Nano Omni on DeepInfraDeepInfra is an official launch partner for NVIDIA Nemotron 3 Nano Omni, the first multimodal model in the Nemotron 3 family — a single open model that understands images, video, audio, documents, and text in one unified inference pass.
Introducing NVIDIA Nemotron 3 Nano Omni on DeepInfraDeepInfra is an official launch partner for NVIDIA Nemotron 3 Nano Omni, the first multimodal model in the Nemotron 3 family — a single open model that understands images, video, audio, documents, and text in one unified inference pass. Best API Providers for GLM-5.1 in 2026<p>GLM-5.1 is available across a growing number of API providers, and the choice between them materially affects cost, latency, and what features you can actually use. The benchmark spread is real: blended pricing runs from $0.74 to $1.70 per 1M tokens across tracked providers, output speed ranges from 33 to 175 t/s, and not every […]</p>
Best API Providers for GLM-5.1 in 2026<p>GLM-5.1 is available across a growing number of API providers, and the choice between them materially affects cost, latency, and what features you can actually use. The benchmark spread is real: blended pricing runs from $0.74 to $1.70 per 1M tokens across tracked providers, output speed ranges from 33 to 175 t/s, and not every […]</p>
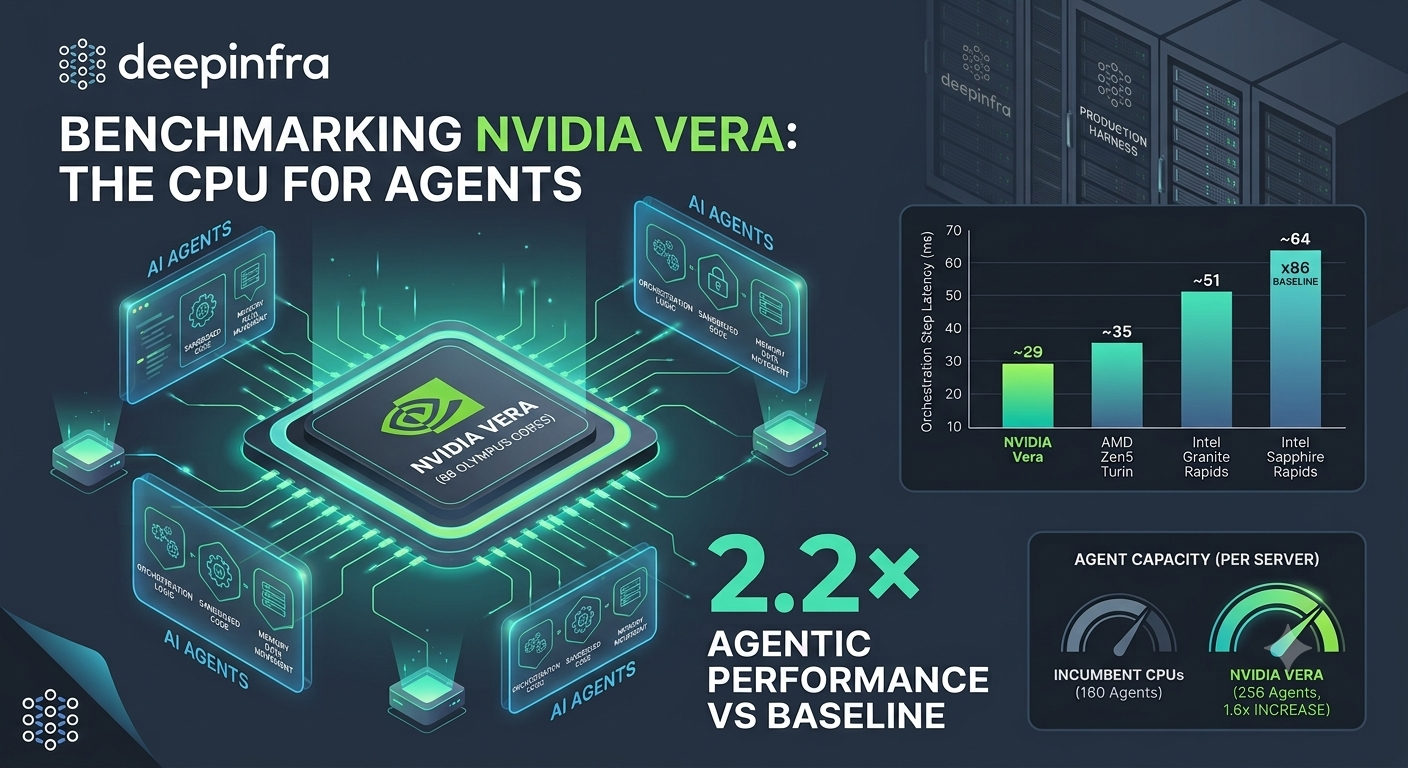 We Benchmarked NVIDIA Vera, the CPU for Agents. Here's What We MeasuredDeepInfra runs AI agents in production, so when NVIDIA built a CPU for agents, we measured it ourselves with our own harness, our own agent, and a methodology we locked before the hardware arrived.
We Benchmarked NVIDIA Vera, the CPU for Agents. Here's What We MeasuredDeepInfra runs AI agents in production, so when NVIDIA built a CPU for agents, we measured it ourselves with our own harness, our own agent, and a methodology we locked before the hardware arrived.


© 2026 DeepInfra. All rights reserved.