DeepInfra raises $107M Series B to scale the inference cloud — read the announcement
 Published on 2026.06.29 by DeepInfraIntroducing the Priority Service Tier: Front-of-Queue Inference When It Counts
Published on 2026.06.29 by DeepInfraIntroducing the Priority Service Tier: Front-of-Queue Inference When It CountsPay 1.5× real-time for priority scheduling and protected capacity.
 Published on 2026.06.19 by Vasilije NovakovicIntroducing the Batch API: Run Large Inference Jobs 20% Cheaper
Published on 2026.06.19 by Vasilije NovakovicIntroducing the Batch API: Run Large Inference Jobs 20% CheaperDeepInfra's new Batch API lets you submit large volumes of completions, chat, and embedding requests as a single asynchronous job—processed within 24 hours at 20% off real-time pricing. It's fully OpenAI-compatible, so if you've used OpenAI's Batch API, you already know how it works.
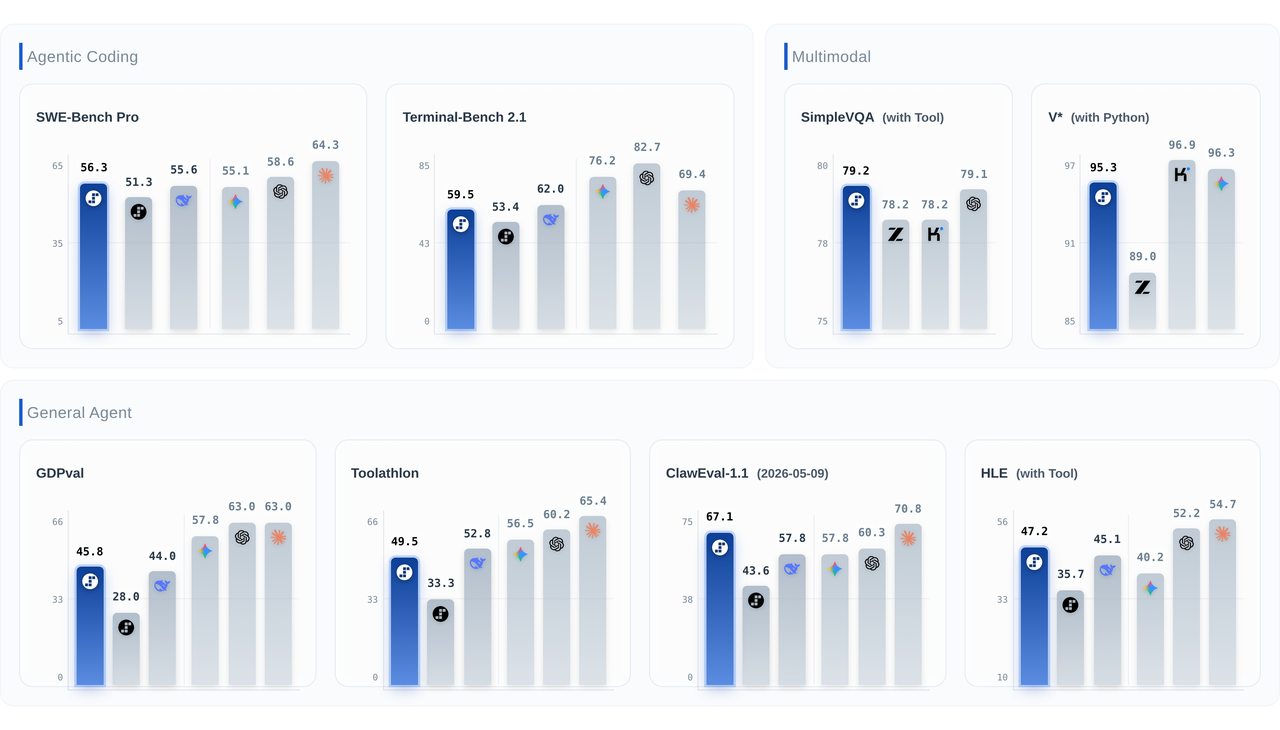 Published on 2026.06.12 by DeepInfraStep 3.7 Flash is Live on DeepInfra: An Agentic, Multimodal Model Built for Production
Published on 2026.06.12 by DeepInfraStep 3.7 Flash is Live on DeepInfra: An Agentic, Multimodal Model Built for ProductionStepFun's Step 3.7 Flash is now live on DeepInfra. It's a 198B-parameter sparse MoE vision-language model with just ~11B active parameters per token, a 256K context window, and three selectable reasoning levels—purpose-built for high-throughput agentic workflows that combine perception, search, and reasoning.
 Published on 2026.06.04 by Yessen KanapinDeepInfra Launches Access to NVIDIA Cosmos 3 World Foundation Models for Physical AI
Published on 2026.06.04 by Yessen KanapinDeepInfra Launches Access to NVIDIA Cosmos 3 World Foundation Models for Physical AIDeepInfra is serving NVIDIA Cosmos 3, the first open world foundation model for physical AI that reasons before it generates, from day zero of its release. Available as two variants—Cosmos 3 Nano and Cosmos 3 Super—these models give developers a cost-efficient foundation for building robots, autonomous vehicles, simulation workflows, and synthetic data generation at scale.
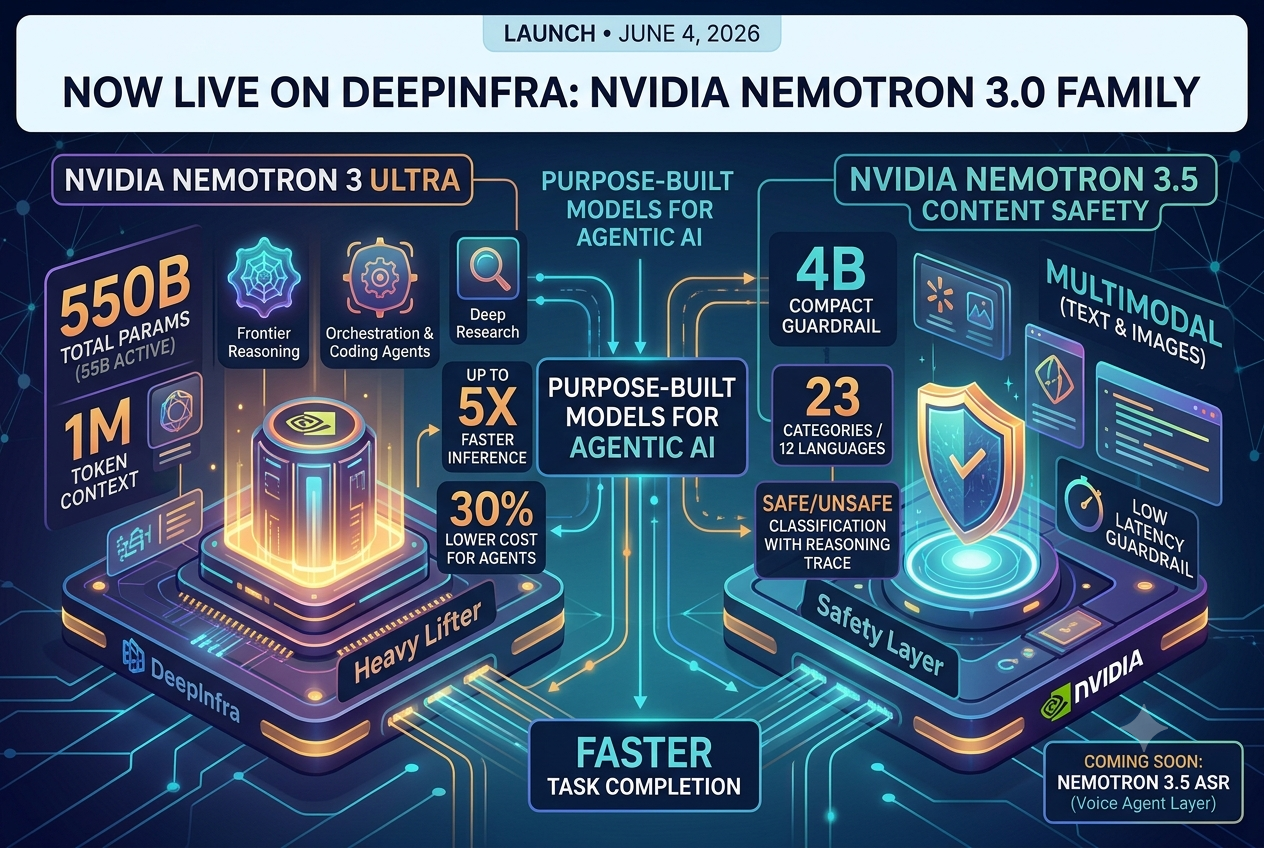 Published on 2026.06.04 by Yessen KanapinNemotron 3 Ultra, 3.5 Content Safety and ASR models are now live on DeepInfra platform.
Published on 2026.06.04 by Yessen KanapinNemotron 3 Ultra, 3.5 Content Safety and ASR models are now live on DeepInfra platform.Nemotron 3 Ultra and Nemotron 3.5 Content Safety are live on DeepInfra as of today. Here's what they are and why we think they're worth your attention.
 Published on 2026.05.26 by DeepInfraOpenClaw Use Cases That Deliver Real ROI
Published on 2026.05.26 by DeepInfraOpenClaw Use Cases That Deliver Real ROIAn OpenClaw agent that reads your email, opens pull requests, and watches a server is only useful if running it doesn’t feel like leaving the meter running. That’s the quiet constraint behind every OpenClaw use cases discussion. Most of the workflows people show off (morning briefings, multi-agent research, ambient monitoring) only make sense if each […]



© 2026 DeepInfra. All rights reserved.