We use essential cookies to make our site work. With your consent, we may also use non-essential cookies to improve user experience and analyze website traffic…
DeepInfra raises $107M Series B to scale the inference cloud — read the announcement

Did you just finetune your favorite model and are wondering where to run it? Well, we have you covered. Simple API and predictable pricing.
Put your model on huggingface
Use a private repo, if you wish, we don't mind. Create a hf access token just for the repo for better security.
Create custom deployment
Via Web
You can use the Web UI to create a new deployment.
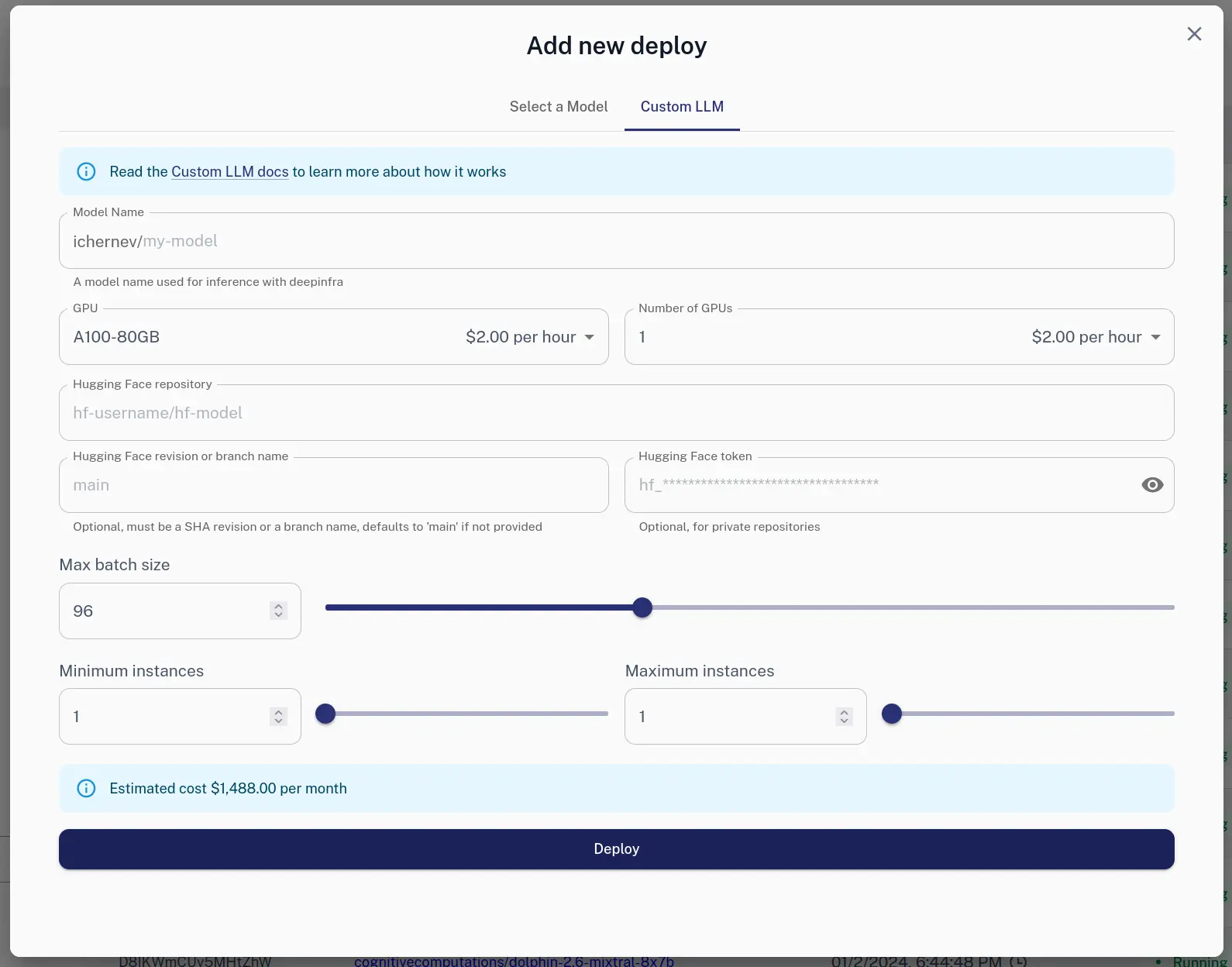
Via HTTP
We also offer HTTP API:
curl -X POST https://api.deepinfra.com/deploy/llm -d '{
"model_name": "test-model",
"gpu": "A100-80GB",
"num_gpus": 2,
"max_batch_size": 64,
"hf": {
"repo": "meta-llama/Llama-2-7b-chat-hf"
},
"settings": {
"min_instances": 1,
"max_instances": 1,
}
}' -H 'Content-Type: application/json' \
-H "Authorization: Bearer YOUR_API_KEY"
Use it
curl -X POST \
-d '{"input": "Hello"}' \
-H 'Content-Type: application/json' \
-H "Authorization: Bearer YOUR_API_KEY" \
'https://api.deepinfra.com/v1/inference/github-username/di-model-name'
For in depth tutorial check Custom LLM Docs.
Related articles How to OpenAI Whisper with per-sentence and per-word timestamp segmentation using DeepInfraWhisper is a Speech-To-Text model from OpenAI.
How to OpenAI Whisper with per-sentence and per-word timestamp segmentation using DeepInfraWhisper is a Speech-To-Text model from OpenAI. Chat with books using DeepInfra and LlamaIndexAs DeepInfra, we are excited to announce our integration with LlamaIndex.
LlamaIndex is a powerful library that allows you to index and search documents
using various language models and embeddings. In this blog post, we will show
you how to chat with books using DeepInfra and LlamaIndex.
We will ...
Chat with books using DeepInfra and LlamaIndexAs DeepInfra, we are excited to announce our integration with LlamaIndex.
LlamaIndex is a powerful library that allows you to index and search documents
using various language models and embeddings. In this blog post, we will show
you how to chat with books using DeepInfra and LlamaIndex.
We will ... A Milestone on Our Journey Building DeepInfra and Scaling Open Source AI InfrastructureToday we're excited to share that DeepInfra has raised $18 million in Series A funding, led by Felicis and our earliest believer and advisor Georges Harik.
A Milestone on Our Journey Building DeepInfra and Scaling Open Source AI InfrastructureToday we're excited to share that DeepInfra has raised $18 million in Series A funding, led by Felicis and our earliest believer and advisor Georges Harik.
How to OpenAI Whisper with per-sentence and per-word timestamp segmentation using DeepInfraWhisper is a Speech-To-Text model from OpenAI.Chat with books using DeepInfra and LlamaIndexAs DeepInfra, we are excited to announce our integration with LlamaIndex.
LlamaIndex is a powerful library that allows you to index and search documents
using various language models and embeddings. In this blog post, we will show
you how to chat with books using DeepInfra and LlamaIndex.
We will ...A Milestone on Our Journey Building DeepInfra and Scaling Open Source AI InfrastructureToday we're excited to share that DeepInfra has raised $18 million in Series A funding, led by Felicis and our earliest believer and advisor Georges Harik.


© 2026 DeepInfra. All rights reserved.