NVIDIA Nemotron 3 Super - blazing-fast agentic AI, ready to deploy today!
Custom LLMs
Documentation
Custom LLMs
Custom LLMs
You can now run a dedicated instance of your public or private LLM on DeepInfra infrastructure.
Overview
There are a number of benefits for running your own custom LLM instance:
- predictable response times
- auto-scaling support
- run your own (finetuned or trained from scratch) model
There are of course some drawbacks:
- pricing is for GPU uptime
It's important to understand that all our publicly available models, like mixtral 8x7, are shared among many users, and this lets us offer very competitive pricing as a result. When you run your own model, you get full access to the GPUs and pay per GPU/hours your model is up. So you have to have a sufficient load to justify this resource.
Usage
Creating a new deployment
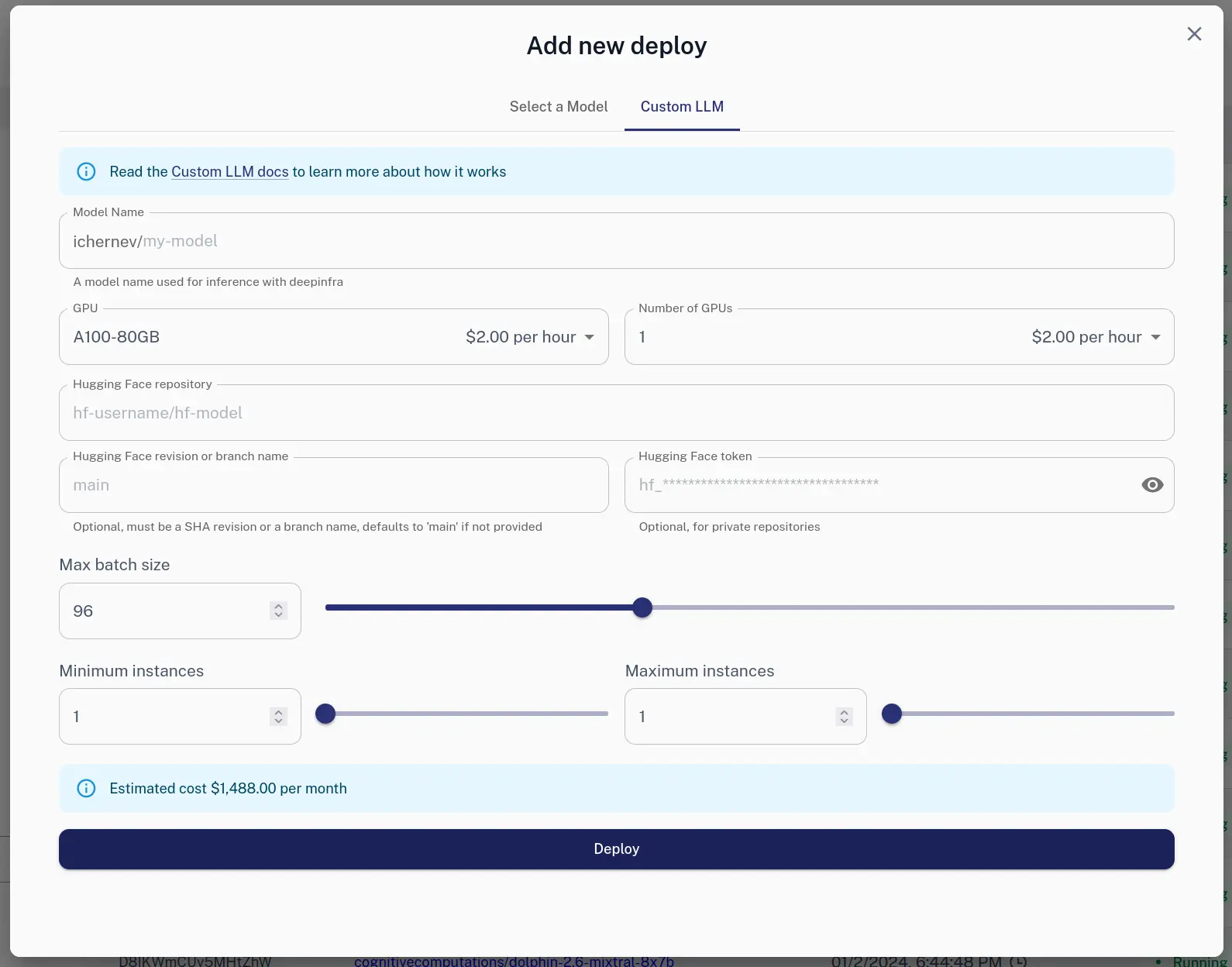
A deployment is a particular configuration of your custom models. It has fixed:
model_name-- the name you'd use when doing inference (generation)gputype -- A100-80GB or H100-80GB supported now, expect more in the futurenum_gpus-- how many GPUs to use, bigger models require more GPUs (it should at least fit the weights and have some leftover for KV cache)max_batch_size-- how many requests to run in parallel (at most), other requests are queued up- weights -- currently Hugging Face is supported (including private repos)
It also has a few settings that can be changed dynamically:
min_instances-- how many copies of the model to run at a minumummax_instances-- up to how many copies to scale during times of higher load
To create a new deployment, use the the Web UI:
Or, using the HTTP API:
curl -X POST https://api.deepinfra.com/deploy/llm -d '{
"model_name": "test-model",
"gpu": "A100-80GB",
"num_gpus": 2,
"max_batch_size": 64,
"hf": {
"repo": "meta-llama/Llama-2-7b-chat-hf"
},
"settings": {
"min_instances": 0,
"max_instances": 1,
}
}' -H 'Content-Type: application/json' \
-H "Authorization: Bearer $DEEPINFRA_TOKEN"
The deploy can be monitored via HTTP, or the Web dashboard.
Please note that the model full name is github-username/model-name. My github
username is ichernev, so the model above will have full name
ichernev/test-model.
Using a deployment
When you create a deployment, the name you specify is prefixed by your github
username. So if I (ichernev) create a model test-model, it's full name will
be ichernev/test-model. You can then use this name during inference, or the
check the model web page:
You can use your model via:
- Web demo page: https://deepinfra.com/FULLNAME
- HTTP APIs (check https://deepinfra.com/FULLNAME/api for details)
- DeepInfra interface
- OpenAI ChatCompletions API
- OpenAI Completions API
Updating a deployment
Once a deployment is running, its scaling parameters can be updated via the deployment details page accessible from Dashboard / Deployments.
via HTTP:
curl -X PUT https://api.deepinfra.com/deploy/DEPLOY_ID -d '{
"settings": {
"min_instances": 2,
"max_instances": 2,
}
}' -H 'Content-Type: application/json' \
-H "Authorization: Bearer YOUR_API_KEY"
You'd need your DEPLOY_ID. It is returned on creation, but also available in
Web Dashboard or via HTTP API
/deploy/list.
Deleting a deployment
When you want to permanently delete / discard a deployment, use:
- the trash icon next to a deployment in Dashboard / Deployments
- DELETE /deploy/DEPLOY_ID
Limitations and Caveats
- We're enforcing a limit of 4 GPUs per user maximum (4 instances x 1 GPU or 1 instance x 4 GPUs, for example). Contact us if you require more.
- We try our best to satisfy all requests, but GPUs are a limited resource and
sometimes there just isn't enough of it. This means that if try you upscale
we might not be able to meet demand (say, you put
min_instances== 3, but we can only run 2). You're only billed for what actually runs. The current numer of running instances is returned in the deploy object - Billing for Custom LLMs will happen weekly, in a separate invoice
- Leaving a custom LLMs running (by mistake) can quickly rack up costs. For example if you forget to shutdown a custom LLM using 2 GPUs on Friday 5pm, and remember about it on Monday at 9am, that will cost you 256 USD (64h * 2 GPUs * 2 USD). Use spending limits in payment settings.
- Quantization is currently not supported, work in progress



© 2026 Deep Infra. All rights reserved.