We use essential cookies to make our site work. With your consent, we may also use non-essential cookies to improve user experience and analyze website traffic…
DeepInfra raises $107M Series B to scale the inference cloud — read the announcement

Getting an API Key
To use DeepInfra's services, you'll need an API key. You can get one by signing up on our platform.
- Sign up or log in to your DeepInfra account at deepinfra.com
- Navigate to the Dashboard and select API Keys
- Create a new API key and save it securely
Your API key will be used to authenticate all your requests to the DeepInfra API.
Deployment
Now lets actually deploy some models to production and use them for inference. It is really easy.
You can deploy models through the web dashboard or by using our API. Models are automatically deployed when you first make an inference request.
Inference
Once a model is deployed on DeepInfra, you can use it with our REST API. Here's how to use it with curl:
curl -X POST \
-F "audio=@/path/to/audio.mp3" \
-H "Authorization: Bearer YOUR_API_KEY" \
'https://api.deepinfra.com/v1/inference/openai/whisper-small'
Related articles Chat with books using DeepInfra and LlamaIndexAs DeepInfra, we are excited to announce our integration with LlamaIndex.
LlamaIndex is a powerful library that allows you to index and search documents
using various language models and embeddings. In this blog post, we will show
you how to chat with books using DeepInfra and LlamaIndex.
We will ...
Chat with books using DeepInfra and LlamaIndexAs DeepInfra, we are excited to announce our integration with LlamaIndex.
LlamaIndex is a powerful library that allows you to index and search documents
using various language models and embeddings. In this blog post, we will show
you how to chat with books using DeepInfra and LlamaIndex.
We will ...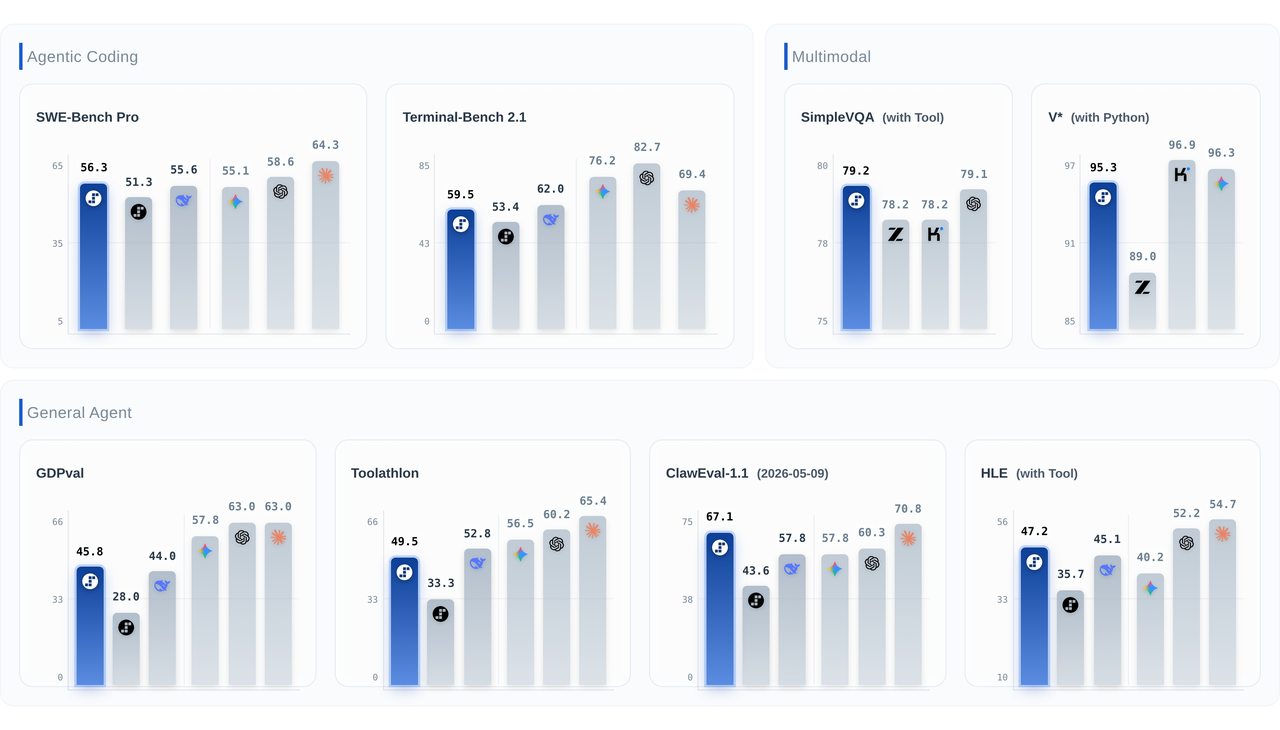 Step 3.7 Flash is Live on DeepInfra: An Agentic, Multimodal Model Built for ProductionStepFun's Step 3.7 Flash is now live on DeepInfra. It's a 198B-parameter sparse MoE vision-language model with just ~11B active parameters per token, a 256K context window, and three selectable reasoning levels—purpose-built for high-throughput agentic workflows that combine perception, search, and reasoning.
Step 3.7 Flash is Live on DeepInfra: An Agentic, Multimodal Model Built for ProductionStepFun's Step 3.7 Flash is now live on DeepInfra. It's a 198B-parameter sparse MoE vision-language model with just ~11B active parameters per token, a 256K context window, and three selectable reasoning levels—purpose-built for high-throughput agentic workflows that combine perception, search, and reasoning. Beat AI Subscription Fatigue With One API<p>Open your company card statement and scroll the recurring charges. Twenty dollars for a chat assistant, twenty more for a coding copilot, fifteen for an image API, another forty for the automation glue that wires them together. None of them is expensive on its own. Together they are a slow leak you stopped noticing months […]</p>
Beat AI Subscription Fatigue With One API<p>Open your company card statement and scroll the recurring charges. Twenty dollars for a chat assistant, twenty more for a coding copilot, fifteen for an image API, another forty for the automation glue that wires them together. None of them is expensive on its own. Together they are a slow leak you stopped noticing months […]</p>
Chat with books using DeepInfra and LlamaIndexAs DeepInfra, we are excited to announce our integration with LlamaIndex.
LlamaIndex is a powerful library that allows you to index and search documents
using various language models and embeddings. In this blog post, we will show
you how to chat with books using DeepInfra and LlamaIndex.
We will ...Step 3.7 Flash is Live on DeepInfra: An Agentic, Multimodal Model Built for ProductionStepFun's Step 3.7 Flash is now live on DeepInfra. It's a 198B-parameter sparse MoE vision-language model with just ~11B active parameters per token, a 256K context window, and three selectable reasoning levels—purpose-built for high-throughput agentic workflows that combine perception, search, and reasoning.Beat AI Subscription Fatigue With One API<p>Open your company card statement and scroll the recurring charges. Twenty dollars for a chat assistant, twenty more for a coding copilot, fifteen for an image API, another forty for the automation glue that wires them together. None of them is expensive on its own. Together they are a slow leak you stopped noticing months […]</p>



© 2026 DeepInfra. All rights reserved.