DeepInfra raises $107M Series B to scale the inference cloud — read the announcement

An OpenClaw agent that reads your email, opens pull requests, and watches a server is only useful if running it doesn’t feel like leaving the meter running. That’s the quiet constraint behind every OpenClaw use cases discussion. Most of the workflows people show off (morning briefings, multi-agent research, ambient monitoring) only make sense if each agent step costs cents, not dollars. On a closed-weight API priced for chat, an autonomous loop that pings the model 40 times an hour is a budget incident waiting to happen.
This article ranks OpenClaw use cases by what actually earns its keep when you run the reasoning on open-weight models hosted on DeepInfra instead of a closed-weight chat API. The angle matters because agent autonomy is a function of unit economics. The more an agent decides on its own (which step is next, which file to open, when to back off), the more inference it burns, and the more the open vs. closed gap widens.
We’ll walk through the use case categories OpenClaw is genuinely good at, name the models that fit each one, and end with the openclaw.json block that wires a DeepInfra provider into the agent.
How we picked these use cases
Not every OpenClaw demo translates into a workflow you’d leave running for six months. Four things separate the OpenClaw use cases that hold up from the ones that only look good in a screen recording.
Start with tool surface. Does the workflow need read-only access (logs, calendars, RSS), write access (drafts, PR comments), or full execute access (bash, file system, deploy commands)? Read-only loops are the safest place to start. Full-execute loops earn their keep, but they need permission scoping.
Then there’s cost sensitivity per step. Some workflows fire one inference per trigger, like an inbox summary at 7am. Others fire dozens of calls per task: a research agent, a multi-agent debate. That second category is where the models on DeepInfra change the math from “weekend project” to “always on.”
Model routing fit is the third lever. Tasks that benefit from swapping models (a cheap classifier for triage, a stronger model for the final draft) reward the single-API pattern more than tasks that run one model end to end.
Last, recovery cost. How bad is it if the agent gets something wrong? A wrong calendar block is annoying. A wrong production deployment is something completely different.
OpenClaw use cases #1: Morning briefings and inbox triage
This is the gateway OpenClaw use case for almost every developer who installs the agent. The shape is consistent: a scheduled trigger fires at 6 or 7am, the agent reads overnight email, calendar entries, GitHub notifications, and maybe a couple of RSS feeds, and posts a summary to WhatsApp, Telegram, or a Slack DM. Inbox triage is the same loop with write access added: classify, archive, draft replies on the top five threads, leave the rest alone.
Two things make this workflow well suited to open-weight inference. First, the prompt is the same shape every day. Open-weight models on DeepInfra hit context caching cleanly when the system prompt and tool list are stable, which knocks the marginal cost down further. Second, the work is summarization and classification, not reasoning over hard math. That’s a sweet spot for DeepSeek-V3.2 ($0.26 per million input tokens at the time of writing) and Qwen3 family chat models. You don’t need to spend Claude-tier tokens to get a clean morning brief.
The reason this matters for the open vs. closed question is volume. A briefing agent that runs twice a day every day, plus inbox triage every couple of hours, is easily 1500 to 3000 calls per month for one person. On a premium closed-weight API priced for one-off chat, that adds up. On DeepInfra, an open-weight model running the same loop is almost an order of magnitude cheaper before you even turn on caching. Cost is the difference between “I tried OpenClaw last weekend” and “I forgot it was running.”
OpenClaw use cases #2: Developer workflows on a long leash
Developer-facing OpenClaw use cases (CI/CD watching, server monitoring, remote PR review, log triage) push harder on the model. You’re no longer summarizing a calendar. You’re reading a stack trace, tracing it through a repo, and deciding whether to open an issue, draft a fix, or page a human.
The model matters more here, and so does the open-weight angle. Qwen3-Coder-480B-A35B is the obvious DeepInfra pick for code-grounded steps because it was trained on a code-heavy corpus and handles tool-call JSON cleanly. For the planning step (which file, which test, which PR), DeepSeek-V3.2 holds its own and stays cheap. A typical OpenClaw setup is: cheap general model for “what is this incident,” code-specialized model for “patch this file,” and a third model only for the rare cases where the first two disagree.
This is where the closed-weight tax gets visible. A “watch the CI” agent that polls every 5 minutes, drills into a failure when one appears, and writes a fix candidate easily ends up doing 200 inference calls before it has done anything you would actually merge. Running that loop on a premium API for a week is real money. Running it on Qwen3-Coder-480B-A35B via DeepInfra (with the same OpenAI-compatible Chat Completions API) is the kind of cost line you stop reviewing. The lower the cost of being wrong, the longer the leash you can give the agent.
OpenClaw use cases #3: Multi-agent workflows with per-task model routing
The OpenClaw use cases that look the most impressive in demos (research pipelines, content audits, autonomous trading sketches) are almost always multi-agent. A planner agent decomposes the task, specialized worker agents handle the steps, and a synthesizer combines the results.
The infrastructure question is: do the worker agents need to share a model? Almost never. A web-scraping worker, a SQL worker, and a writing worker have nothing in common except the contract with the planner. This is where a single OpenAI-compatible endpoint hitting a catalog of open-weight models pays for itself: each subtask routes to whichever DeepInfra-hosted model fits, without juggling four provider SDKs and four billing dashboards.
An OpenClaw skill that wants to step outside the agent’s default chat path and pick a model per call looks like this:
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ["DEEPINFRA_TOKEN"],
base_url="https://api.deepinfra.com/v1/openai",
)
def route(task: str, content: str) -> str:
model = {
"classify": "Qwen/Qwen3-14B",
"code": "Qwen/Qwen3-Coder-480B-A35B-Instruct",
"write": "deepseek-ai/DeepSeek-V3.2",
}[task]
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": content}],
)
return response.choices[0].message.contentOne client, one auth token, and three models. The cheap classifier handles intake at fractions of a cent per call. The code model handles the mechanical work. But the expensive model only runs when the workflow commits to a draft a human will read. That separation is awkward on a single closed-weight API, where every call hits the same tier regardless of how trivial the step is.
There’s a second reason this matters for autonomy, and it’s the one that sneaks up on you. A multi-agent loop reacts to what the worker produced. The longer it runs unattended, the more inference it burns. Routing each step to the cheapest model that can do it is the difference between an agent you trust overnight and one you babysit. Open-weight routing is what makes the autonomy decision feasible at all, well before it shows up as savings.
OpenClaw use cases #4: Finance, research pipelines, and ambient monitoring
The fourth cluster of OpenClaw use cases is the always-on category. A finance agent that watches a watchlist and pings you on signals. A research agent that pulls daily papers from a few feeds, dedupes, ranks by topic similarity, and writes a 200-word summary. A home-camera or sensor monitor that watches a stream, flags movement during work hours or a fall in an elderly relative’s room, and triggers a notification when something is off.
These workflows share a profile: high call volume, modest reasoning depth per call, and a low tolerance for surprise on the bill. Most of the OpenClaw guides skip hardware integration entirely, even though OpenClaw’s tool surface, plus a vision-capable open-weight model, makes it one of the more practical entry points for ambient AI.
The math here gets unfriendly fast on a closed-weight API. A camera-watching loop pulling one frame every 30 seconds is 2,880 inference calls per day, before you add a second camera. A vision-capable open-weight model on DeepInfra (a Qwen3-VL variant like the 30B-A3B model, which activates only 3B parameters per token, or Llama 4 Scout) running the same loop is the only version of this workflow most people can afford to leave on. The open vs. closed gap isn’t academic when the workload is genuinely continuous.
OpenClaw use cases at a glance: model picks by job
Starting defaults for wiring OpenClaw use cases to the right model on DeepInfra. Adjust after you see real workloads.
| Use case category | Recommended open-weight model | Why this fit |
|---|---|---|
| Morning briefings and inbox triage | DeepSeek-V3.2 | Cheap summarization, long context |
| Calendar and task assistant | Qwen3 Instruct family | Fast classifier, clean tool-call JSON |
| CI/CD watching and PR review | Qwen3-Coder-480B-A35B | Code-grounded, clean diff handling |
| Multi-agent planner | DeepSeek-V3.2 | Stepwise reasoning for decomposition |
| Multi-agent worker (generic) | Qwen3 Instruct family | Throughput and price for routine subtasks |
| Camera or sensor monitoring | Qwen3-VL family | Vision pricing tolerable for continuous loops |
| Final draft / decision step | DeepSeek-V3.2 | Higher-quality commit step |
Any of these picks can be swapped for a peer model on the DeepInfra catalog without rewriting your agent code, since the API surface stays the same.
How to wire DeepInfra into OpenClaw in five minutes
Every OpenClaw use case above is reachable from the same install because OpenClaw treats model providers as plug-ins. Point it at any OpenAI-compatible endpoint, register the models you care about, and reference them from your agents and skills.
DeepInfra exposes an OpenAI-compatible Chat Completions API at https://api.deepinfra.com/v1/openai, which is the same surface OpenClaw’s openai-completions provider type expects. The configuration lives in ~/.openclaw/openclaw.json. A minimal block for adding DeepInfra as a custom OpenClaw provider with two models registered looks like this:
{
models: {
providers: {
deepinfra: {
baseUrl: "https://api.deepinfra.com/v1/openai",
apiKey: "${DEEPINFRA_TOKEN}",
api: "openai-completions",
models: [
{ id: "deepseek-ai/DeepSeek-V3.2", name: "DeepSeek-V3.2" },
{ id: "Qwen/Qwen3-Coder-480B-A35B-Instruct", name: "Qwen3 Coder 480B" },
],
},
},
},
agents: {
defaults: {
model: { primary: "deepinfra/deepseek-ai/DeepSeek-V3.2" },
},
},
}A few things to flag. The model IDs keep their slashes (DeepInfra uses the vendor/model namespace), so OpenClaw will reference them as deepinfra/deepseek-ai/DeepSeek-V3.2 when you wire them into agents or skills. The apiKey value uses environment variable substitution rather than a hardcoded token. Set DEEPINFRA_TOKEN in your shell and OpenClaw resolves it at startup.
If you already have other providers in your config, add mode: “merge” at the top of the models block so OpenClaw merges entries instead of replacing them. Skipping this is the common first-edit foot-gun.
Once that is in place, every OpenClaw skill that calls “the primary model” runs on DeepInfra. To override per-agent, reference the full ID (deepinfra/Qwen/Qwen3-Coder-480B-A35B-Instruct) in that agent’s settings. For the per-call routing shown earlier, bypass the agent defaults and call the DeepInfra endpoint directly from a Python skill using the OpenAI SDK. The OpenClaw side doesn’t need to know which model that skill picked.
That’s the whole integration. No SDK swap and no provider adapter to maintain.
Which OpenClaw use case to start with
If you’re picking your first workflow, pick by recovery cost first and model cost second.
- Go with morning briefings if you want a safe, daily, read-only loop that proves the agent works without risk. Wire it to DeepSeek-V3.2 on DeepInfra and forget about it.
- Go with developer workflows (CI watching, PR review) if you already trust agents and want concrete time savings. Wire the code steps to Qwen3-Coder-480B-A35B.
- Go with multi-agent or ambient monitoring only after you have a workflow you trust running for a couple of weeks. These are the use cases where open-weight inference becomes the precondition for running them at all.
Browse the full catalog at deepinfra.com/models, grab a token, and drop the config above into ~/.openclaw/openclaw.json. Questions or workloads we should test next: feedback@deepinfra.com, the DeepInfra Discord, or @DeepInfra on X.
 GLM-5 API Benchmarks: Latency, Throughput & Cost<p>GLM-5 is the latest open-weights reasoning model released by Z AI (Zhipu AI) in February 2026, characterized by high “thinking token” usage. It is a Mixture of Experts (MoE) model with 744B total parameters and 40B active parameters, scaling up from GLM-4.5’s 355B parameters. The model was pre-trained on 28.5T tokens and features a 200K+ […]</p>
GLM-5 API Benchmarks: Latency, Throughput & Cost<p>GLM-5 is the latest open-weights reasoning model released by Z AI (Zhipu AI) in February 2026, characterized by high “thinking token” usage. It is a Mixture of Experts (MoE) model with 744B total parameters and 40B active parameters, scaling up from GLM-4.5’s 355B parameters. The model was pre-trained on 28.5T tokens and features a 200K+ […]</p>
 Inference Economics: True AI Costs at Scale<p>Most teams discover their inference economics the same way: a production bill arrives that looks nothing like the number they expected. The per-token price seemed small enough during testing. Then real traffic showed up, agents started chaining calls, RAG pipelines bloated the context window, and suddenly the math looked completely different. Token prices have fallen […]</p>
Inference Economics: True AI Costs at Scale<p>Most teams discover their inference economics the same way: a production bill arrives that looks nothing like the number they expected. The per-token price seemed small enough during testing. Then real traffic showed up, agents started chaining calls, RAG pipelines bloated the context window, and suddenly the math looked completely different. Token prices have fallen […]</p>
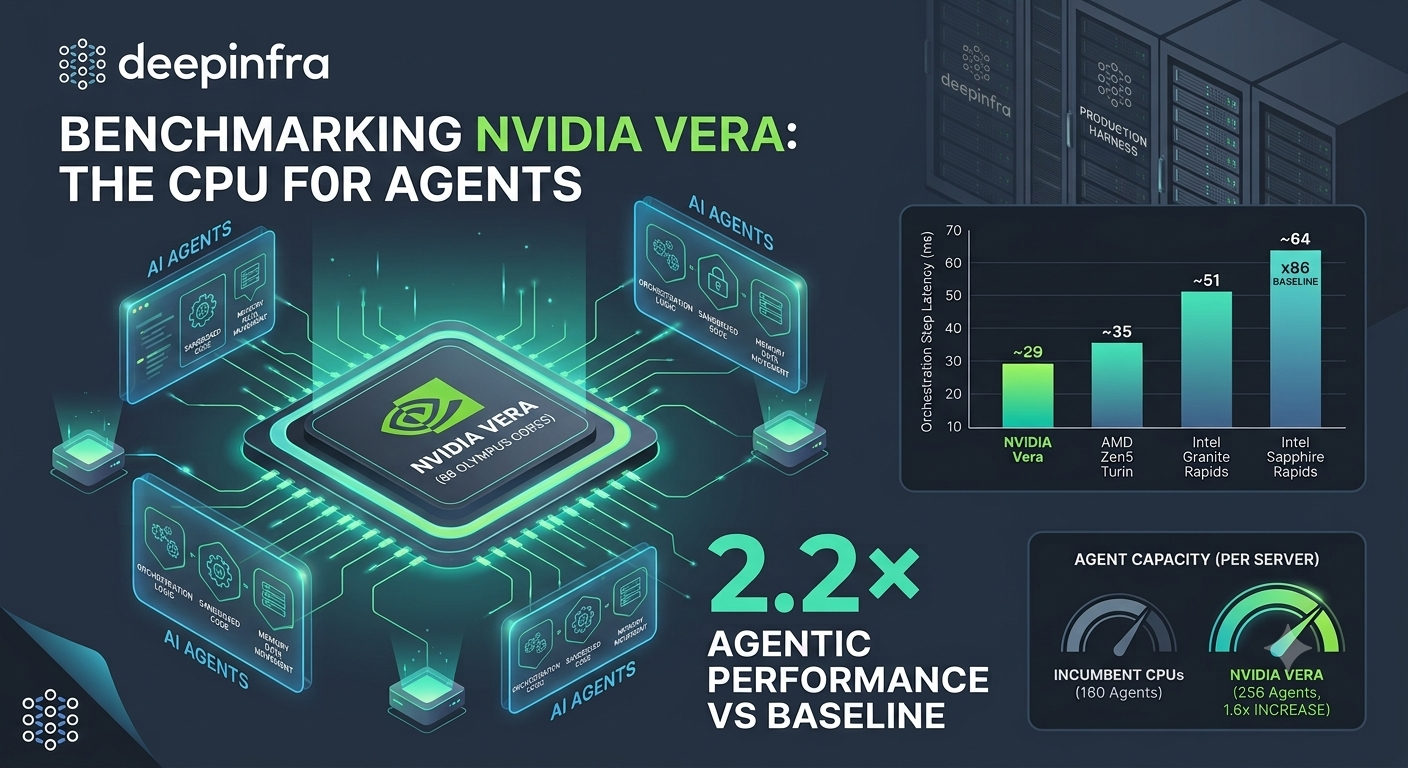 We Benchmarked NVIDIA Vera, the CPU for Agents. Here's What We MeasuredDeepInfra runs AI agents in production, so when NVIDIA built a CPU for agents, we measured it ourselves with our own harness, our own agent, and a methodology we locked before the hardware arrived.
We Benchmarked NVIDIA Vera, the CPU for Agents. Here's What We MeasuredDeepInfra runs AI agents in production, so when NVIDIA built a CPU for agents, we measured it ourselves with our own harness, our own agent, and a methodology we locked before the hardware arrived.


© 2026 DeepInfra. All rights reserved.