DeepInfra raises $107M Series B to scale the inference cloud — read the announcement
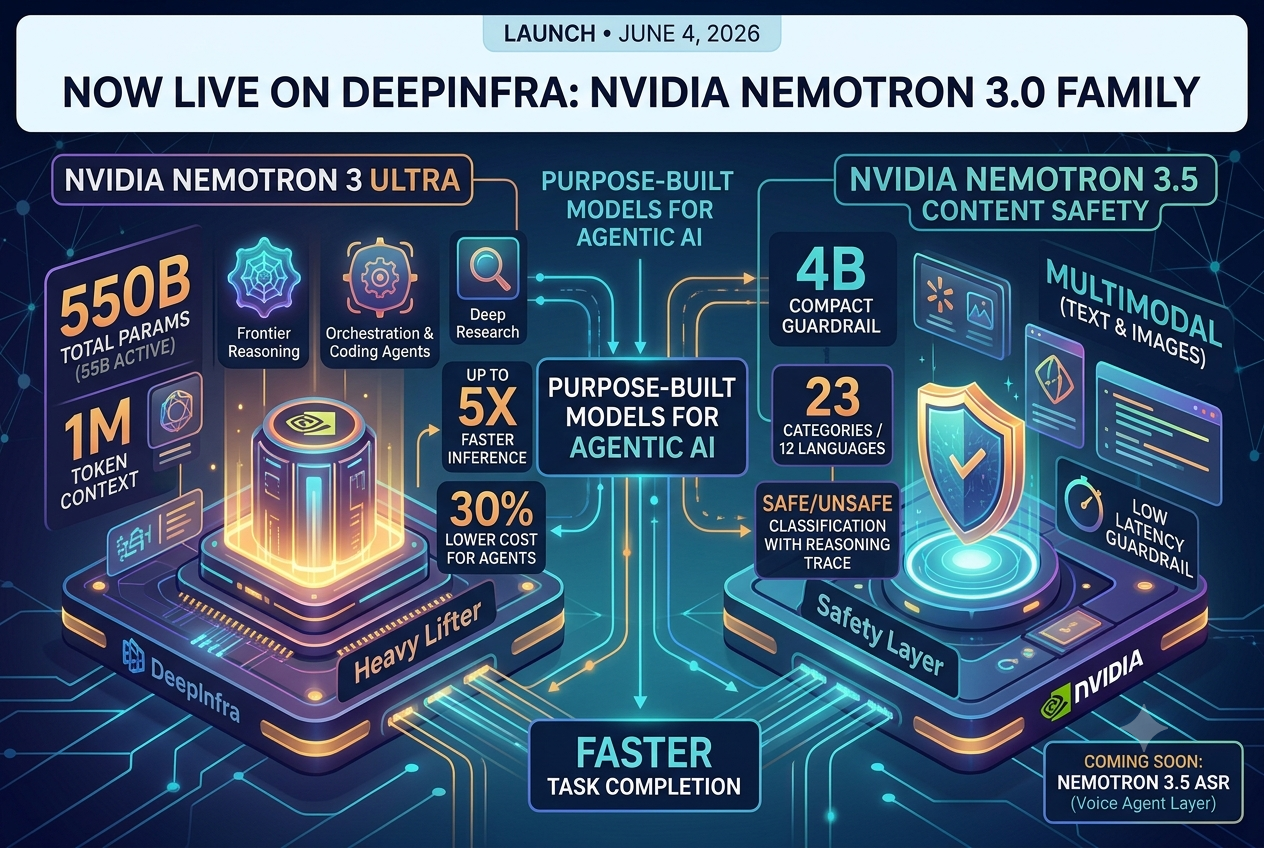
We've been following NVIDIA Nemotron work closely, and we're excited to make Nemotron 3 Ultra and Nemotron 3.5 Content Safety available on DeepInfra from day 0. These aren't just more models to add to the catalog. Nemotron is built around a specific idea about how agentic AI should work, and we think that idea is right.
The idea
Most benchmarks still measure model quality in isolation. But if you're building agentic systems that plan, call tools, delegate work, loop, and eventually complete a task, then you need ot measure of task completion.
"The right measure isn't simply model quality. It's the speed of task completion."
That philosophy shows up most clearly in Nemotron 3 Ultra, which is designed to deliver up to 5x faster inference and up to 30% lower cost for long-running agent workflows.
The broader Nemotron family extends that same idea across the agent stack. Instead of one model that tries to do everything, each model is purpose-built for a specific role—reasoning, speech, safety, and more—so developers can use the right one for each job.
What's live today
Nemotron 3 Ultra
550B · 55B active · 1M context · BF16 + NVFP4
Nemotron 3 Ultra is built for, frontier reasoning, orchestration, coding agents, deep research, and complex enterprise workflows. It delivers up to 5x faster inference and up to 30% lower cost for agentic workloads while supporting up to 1M token context.
Nemotron 3.5 Content Safety
4B · multimodal · 23 categories · 12 languages
A compact safety model that handles text, images, and custom policies. It outputs a safe/unsafe classification plus a reasoning trace, and can be used as an inference-time guardrail, as a judge for LLM safety testing and evaluation, or with the accompanying training dataset to post-train models for safer behavior. Designed to run as a guardrail layer in your pipeline without adding a lot of latency.
These two complement each other naturally. Nemotron 3 Ultra does the heavy lifting, while the safety models keeps the agents things in check. Both are available via our standard API, same as everything else on DeepInfra.
Nemotron 3.5 ASR
0.6B · Streaming · ~40 language-locales
Real-time streaming ASR built for voice agents. Cache-aware architecture means true chunk-by-chunk processing — no recomputation, no buffering lag — designed for high-concurrency live workloads. Supports 40 language locales with native punctuation and capitalization, runtime-configurable latency modes, and word boosting for domain-specific vocabulary. The voice layer for your agent stack, available on DeepInfra now.
Get started
All three models are live right now on DeepInfra and available through our standard API. If you've used DeepInfra before, nothing changes, same API, same setup. If you're new, it takes about two minutes to get a key and run your first call.
→ Explore models: models page
→ View docs: DeepInfra docs
 Qwen3.5 9B API Benchmarks: Latency, Throughput & Cost<p>About Qwen3.5 9B Qwen3.5 9B is the flagship of Alibaba’s Qwen3.5 Small Model Series, released on March 2, 2026. It is a dense multimodal model combining Gated Delta Networks (a form of linear attention) with a sparse Mixture-of-Experts system, enabling higher throughput and lower latency during inference compared to traditional dense architectures. The architecture utilizes […]</p>
Qwen3.5 9B API Benchmarks: Latency, Throughput & Cost<p>About Qwen3.5 9B Qwen3.5 9B is the flagship of Alibaba’s Qwen3.5 Small Model Series, released on March 2, 2026. It is a dense multimodal model combining Gated Delta Networks (a form of linear attention) with a sparse Mixture-of-Experts system, enabling higher throughput and lower latency during inference compared to traditional dense architectures. The architecture utilizes […]</p>
 Best Models for OpenClaw: Top Picks for Agentic Workloads<p>When you configure OpenClaw for the first time, the model picker looks like a minor config detail. It isn’t. The model you connect decides whether your agents complete tasks reliably or fall apart halfway through a multi-step workflow. It sets what you pay per completed job, not just per token. And it determines whether your […]</p>
Best Models for OpenClaw: Top Picks for Agentic Workloads<p>When you configure OpenClaw for the first time, the model picker looks like a minor config detail. It isn’t. The model you connect decides whether your agents complete tasks reliably or fall apart halfway through a multi-step workflow. It sets what you pay per completed job, not just per token. And it determines whether your […]</p>
 NVIDIA Nemotron 3 Super: Model Overview & Integration Guide<p>The NVIDIA Nemotron 3 Super is a state-of-the-art 120-billion parameter hybrid Mixture-of-Experts (MoE) model designed to bridge the gap between high-compute efficiency and extreme accuracy. Engineered specifically for the next generation of AI development, Nemotron 3 Super excels in multi-agent applications, specialized agentic systems, and complex reasoning tasks. By utilizing a sophisticated architecture that activates […]</p>
NVIDIA Nemotron 3 Super: Model Overview & Integration Guide<p>The NVIDIA Nemotron 3 Super is a state-of-the-art 120-billion parameter hybrid Mixture-of-Experts (MoE) model designed to bridge the gap between high-compute efficiency and extreme accuracy. Engineered specifically for the next generation of AI development, Nemotron 3 Super excels in multi-agent applications, specialized agentic systems, and complex reasoning tasks. By utilizing a sophisticated architecture that activates […]</p>



© 2026 DeepInfra. All rights reserved.